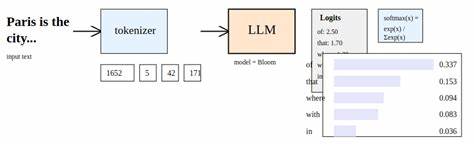
随着大型语言模型(LLM)在自然语言处理领域的广泛应用,如何有效判断模型输出结果的可信度成为行业关注的焦点。模型生成的文本虽然具备高度的语言流畅性,然而其内在的预测自信度常常难以直接获取和解读。为了应对这一挑战,业界和学术界积极探索各种方法,期望通过量化模型自身的置信水平,辅助用户进行更明智的决策。 大型语言模型的置信度,通常与其生成特定词汇或符号的概率密切相关。每当模型输出一个词元,它都会对应一个概率分布,反映其对该词元出现的确信程度。传统中通过对数概率(log probability,简称logprob)来衡量这一置信度,由于概率数值小且多为负数,对数形式更便于数学运算和分析。
然而,单纯依赖对数概率直接推断模型的置信度,面临着准确性不足的问题。实践中发现,logprob值普遍偏高,且在不同质量的输出间区分度有限。这种现象影响了对模型输出可靠性的客观评价,降低了实际应用中的决策支撑作用。 针对这一困境,研究者提出了一种基于关键-值(key-value)结构的置信度提取方法。该方法通过让模型以JSON格式返回任务问题(关键)及对应答案(值),增强了上下文语境对答案生成概率的关联性。例如在分类任务中,将问题简述作为键,分类结果作为对应值;在问答任务中,则将问题描述作为键,答案作为值。
此结构便于对模型输出的每个键值对分别计算和聚合对应词元的logprob,从而获得细粒度的置信度分数。 具体操作流程首先包括对模型返回的JSON响应解析,将各个键值对分拆成相应词元序列。随后,将每个词元的对数概率进行累加,合成代表整个键值对联合概率的指标。通过指数还原,将累积的logprob转化为概率形式,实现对该字段注入的整体置信度评估。这种分层的方法不仅能够捕获答案本身的生成概率,还融合了问题上下文的影响,提升了置信评分的精准度和稳定性。 该技术的优势在于其广泛的适用性。
在发票信息提取中,诸如总金额、开票日期、税率等关键信息,都可以通过此方法获得对应的置信度分数,帮助企业优先检测和复核低置信度数据点,提高整体数据质量和业务自动化水平。此外,该方法也适用于分类任务和问答系统,通过概率细化使输出结果更可信赖,减少错误传递风险。 实验验证表明,通过调整置信度阈值,能够显著提升关键字段的准确率。提高阈值意味着只采纳模型高度确定的输出,虽覆盖率有所下降,但准确性大幅增强。此权衡关系对于风险敏感型场景尤为重要,使系统能够在准确性与覆盖面间灵活调整,满足不同业务需求。 在稳健性测试中,将JSON键值对顺序打乱或仅输出单个键值对,方法依然表现出强大的适应性和可信度判别能力,证明了算法的通用性和健壮性。
当然,实际应用中需要结合具体任务合理设计输出结构。某些情况下,多个键值对共同存在能增强单字段置信度,而在其他场景则建议简洁输出以维持结果清晰。针对复杂嵌套JSON结构或包含特殊字符的令牌,未来的研究将继续优化词元处理,降低潜在异常波动对可信度评估的影响。 目前,该方法已开源并提供了易用的Python库llm_confidence,方便开发者集成至现有流程。通过简洁接口,用户可以轻松调用日志概率处理模块,自动计算每个字段的置信度,为模型输出提供可信度量化,使人工智能系统更稳健可靠。 总结来看,置信度量化是将大型语言模型应用推向深度可靠阶段的关键一步。
通过将传统对数概率转换为结构化信心评分,此方法不仅提升了模型的透明度,也为自动化数据处理、风险管理等领域注入新的精度保障。随着技术不断迭代,结合更多元的模型行为分析,有望进一步完善置信度评估框架,推动人工智能应用更广泛、安全地落地。鼓励广大技术人员尝试并改进此方法,携手打造更可信的智能时代。