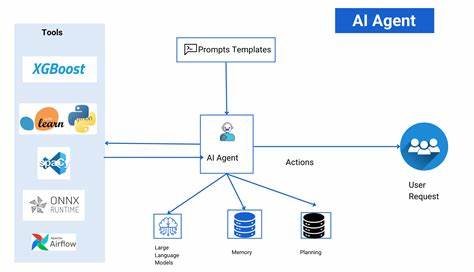
Kubernetes作为当前最流行的容器编排平台,已经成为AI和机器学习等高性能计算任务的首选解决方案。然而,随着越来越多的工作负载依赖GPU和其他专用加速硬件,Kubernetes在处理这些设备相关的Pod故障时面临前所未有的挑战。设备故障可能导致训练任务中断、性能显著下降,甚至影响整个集群的稳定性。理解这些失败模式,以及如何有效管理,成为现代云原生架构设计中不可忽视的重要课题。 AI和机器学习工作负载对硬件的需求具有鲜明特点。训练阶段通常资源密集,往往需要整台机器形成Pod群组(gang),任务持续时间长达数天甚至数月。
任何单个Pod的失败都可能牵连整个训练的步骤重启,从而导致极高的计算资源浪费和时间延误。相较之下,推理阶段通常是长期运行,Pod规模从节点内部分设备到跨多节点资源不等,且常需下载大规模模型文件。正因如此,这些工作负载突破了传统Kubernetes资源假设,带来了调度与故障恢复上的全新难题。 传统的资源管理模型中,Kubernetes通常视资源为固定且持续可用的,如CPU和内存。然而对于GPU等特殊设备,硬件故障可能发生且复杂多变。Kubernetes目前缺乏对设备故障的细粒度感知和智能处理机制,这使得设备故障带来的中断成本非常高昂。
设备插件负责通告节点设备的可用性,但一旦设备出现部分或完全失效,Kubernetes仅能简单通过减少可用设备数量来体现,并不具备更完善的故障隔离与动态替换能力。 设备故障对作业的影响极为严峻。单点设备失败可能导致整任务进度阻塞,尤其是在训练过程中。这种情况有赖于人工进行节点重启或者重新调度Pod,过程耗时且缺乏自动化。当前社区内涌现了许多基于健康控制器(health controller)的自定义解决方案,它们通过监控节点设备状态,并在检测到异常时进行节点层面上的重启,尽管存在根因难以定位、检测延时高以及对上下游任务感知不足等问题,但这类方案在一定程度上缓解了设备故障带来的影响。 针对训练型作业,Pod失败策略也作为一种补充方案被提出。
Pod可自定义特定的错误码以指示设备问题,并配合Pod Failure Policy做出特殊处理。然而这类方案受限于Kubernetes对失败状态表达能力不足,且主要适用于具有restartPolicy为Never的Job类型,对于一般用途Pod的容错适应性依然有限。由于AI/ML作业本身的高度复杂性及跨Pod协作的紧密关联性,单纯依靠Pod失败策略往往难以完全覆盖故障场景。 此外,一些设计为推理服务的场景中,技术团队借助自定义的Pod监控器(Pod watcher)来动态感知设备状态并进行补救操作。例如,监控器通过Pod资源接口检测绑定设备的健康信息,一旦发现设备异常即可主动删除相应Pod,促使ReplicaSet在健康设备上重建新Pod。此机制有效防止Pod持续绑定故障设备导致的不可用状态,但该方案执行需要较高权限,且实现复杂且依赖于外部组件的配合,仍有提升空间。
另一种常见问题是容器内代码本身的失败。Kubernetes对容器失败有基本的自动重启机制和Pod重调度策略,但通常缺乏足够的细节来区分故障性质及其对整体作业的影响。对于规模庞大的训练任务而言,若某Pod失败需整体同步重启更多Pod以保持任务一致,传统方法既费时又浪费资源。当前存在一些依赖外部编排器的DIY解决方案,尝试在Pod内部或集群层面编排更细粒度的重启策略,但这些方案通常十分脆弱,需要Kubernetes引入更多扩展点来支持此类逻辑变得更稳健和易用。 除完全失效之外,设备性能退化也是一个日益突出的问题。复杂的硬件堆栈与驱动环境可能导致设备功能虽存,但表现低于预期,造成训练速度明显下降。
Kubernetes目前尚无机制表达或监测设备的性能降级,依赖人工通过训练指标异常来察觉。硬件供应商及云服务商在此领域的支持还处于起步阶段,相关的故障检测和自动化修复工具亦多为定制与试验性质。 在驱动和基础设施层面,设备插件与驱动的兼容性及稳定性依然是关键。硬件驱动需与设备型号和应用环境精确匹配,且兼容其他依赖驱动,否则将直接导致设备不可用。Kubernetes提倡监控设备插件与驱动的健康状况,推行分阶段升级和金丝雀发布策略以最大程度减少中断风险。不过,驱动不兼容往往造成故障难以快速定位,用户需持续跟进社区最佳实践和厂商更新。
展望未来,Kubernetes社区通过SIG Node积极推动多个方向的创新研发和规范完善。完成设备资源健康状态(Resource Health Status)向Pod状态报告的集成是关键步骤,它为设备失效信息提供了统一接口,方便上层调度和控制逻辑利用。设备失败相关特性如使Pod Failure Policy支持更多重启策略、支持调度器脱钩Pod并重新分配设备、以及在设备调度层加入设备健康信息等也在规划和开发中。 另外,为支持AI/ML工作负载对失败恢复的苛刻需求,提升容器失败的处理成本效益成为重点。Kubernetes计划强化容器内重启、原地重启以及快照恢复等能力,减少因失败重调度带来的延迟和资源浪费。在规模庞大训练任务中,允许批量Pod联合快速恢复将极大提高作业效率和资源利用率。
设备退化问题预计还将借助云供应及硬件厂商支持,结合丰富的监控数据和自动化运维工具逐步形成较成熟的生态。社区也鼓励用户参与反馈和共创最佳实践,推动更完善的信号检测和轻量化故障自动恢复框架。 综合来看,虽然管理带设备的Kubernetes Pod失败极具挑战,但凭借成熟的生态体系和不断进步的扩展能力,Kubernetes仍是高性能计算领域的首选容器平台。理解设备故障的多样模式,结合现有及未来工具和机制,将显著提升AI/ML任务的稳定性和效率。随着更多设备智能感知与协同恢复机制落地,未来容器编排平台在故障自愈与资源动态调优方面的表现值得期待。云原生社区继续携手创新,一起破解设备故障难题,为专用硬件发挥最大潜力保驾护航。
。