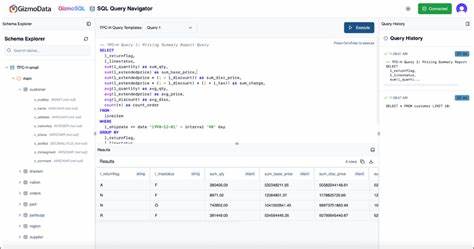
近年来,随着数据量的爆炸性增长,能够高效处理大规模数据集的数据库技术成为行业关注的焦点。传统的分布式计算框架如Spark、Hadoop虽然在处理大数据方面有一定优势,但复杂的集群配置、较高的维护成本以及网络开销等问题阻碍了其广泛应用。GizmoSQL的出现为大数据分析带来了全新的可能性,它通过结合DuckDB和Apache Arrow Flight SQL技术,实现了对海量数据的高效交互式查询。在最近完成的1万亿行挑战中,GizmoSQL展现了其令人瞩目的性能和成本优势,推动大数据查询进入一个崭新的时代。 GizmoSQL的成功离不开其创新的架构设计。DuckDB作为内嵌式分析数据库引擎,专为快速读取和处理列式数据格式而优化,特别是对Parquet文件的支持极为出色。
Apache Arrow Flight SQL协议则负责高效的客户端与服务器间通信,极大提升了数据传输的速度和稳定性。通过这两者的有机结合,GizmoSQL实现了不仅对于持久化数据的查询速度提升,更极大降低了数据预处理和导入的时间成本。 本次1万亿行挑战中,GizmoSQL在AWS的r8gd.metal-48xl实例上执行。该实例搭载了192个基于Graviton4架构的vCPU,配置高达1536GiB的内存和11.4TB的RAID0 NVMe存储,充分释放硬件性能潜力。挑战数据集为2.3TB的Parquet文件,分布在100,000个文件中,每个文件包含约1,000万条数据记录。面对如此庞大的数据规模,GizmoSQL仅用11分24秒完成了数据的从S3的拷贝,并在冷启动环境下执行挑战查询仅需2分22秒,热启动环境更缩短至2分09秒。
令人惊讶的是,使用SQL语句SELECT COUNT(*)对这1万亿行数据进行统计的时间竟然只有21.8秒,显示了其极致的性能表现。 此次挑战不仅展示了GizmoSQL在数据处理速度上的优势,也体现了其极佳的成本效益。因采用了AWS的按需和Spot实例,执行成本被控制在每次查询0.11美元左右。相较于传统依赖分布式计算集群的做法,省却了复杂的集群管理和运维,大幅降低了使用门槛和经济成本。 技术实现上,GizmoSQL之所以能达到如此水平,与其对Parquet格式的深度优化密不可分。Parquet作为列式存储格式,具备高压缩率和高效的列级读取能力,而DuckDB利用向量化处理和现代CPU指令集加速,极大提升了对Parquet文件的查询效率。
同时,Apache Arrow Flight SQL协议带来了高速数据流传输,使客户端查询能够以极低延迟访问海量数据。这种集成方案在性能和灵活性上都显得尤为突出。 GizmoSQL的成功对于大数据分析生态具有重要启示意义。首先,它证明了非分布式环境下依然可以实现海量数据的交互式查询,从而挑战传统大数据处理的思维定式。其次,简单易用且资源高效的架构极大降低了企业上手门槛,使得更多业界用户能够轻松开展大数据分析,促进数据驱动的业务转型。最后,开源的GizmoSQL项目为技术社区贡献了强大工具,推动数据处理技术的持续创新与发展。
未来,随着云计算与大数据技术的持续融合,数据分析对实时性和交互性的要求愈发严苛。GizmoSQL所代表的无分布式高性能分析数据库有望在金融风控、物联网、广告技术、科学研究等多个领域得到广泛应用。它的快速查询能力将极大缩短数据分析周期,提升决策效率,助力企业抢占市场先机。 综上所述,GizmoSQL完成1万亿行挑战不仅是一项技术创新的里程碑,更是大数据处理领域的革命性进展。通过结合DuckDB的端到端查询优化和Arrow Flight SQL的高速数据通信,它成功打破了海量数据交互式分析的性能瓶颈。凭借成本低廉、部署简单和卓越的性能表现,GizmoSQL为海量数据时代的业务分析提供了全新的解决方案,引领我们迈向更高效、灵活的大数据未来。
。