随着人工智能技术的快速发展,语言模型正日益成为推动技术创新和产业变革的重要力量。大型语言模型(LLM)凭借其强大的自然语言处理能力,广泛应用于自动问答、内容生成、机器翻译等多个领域。然而,如何科学、公正、高效地评估这些模型的综合能力,成为业界关注的焦点。MMLU(Massive Multitask Language Understanding)作为业界领先的多任务语言理解基准,能够全面反映模型在各种复杂语言任务中的表现,因而成为评测大型语言模型性能的重要工具。近年来,随着云计算平台和API服务的普及,开发者能够在不同LLM端点轻松运行MMLU测试,从而对比不同模型的实际能力和适配性。本文将深入探讨如何在各种主流API端点上运行MMLU基准测试,分析公开模型的测试结果,并探讨这一工具如何助力AI生态系统的发展与优化。
大型语言模型已进入变革期,性能和效率的衡量标准日益多元。传统的单一测试指标难以全面反映模型在真实应用中的表现。MMLU通过涵盖语言理解、推理和信息检索等多种任务,提供了一个细致、多维度的性能画像。如今,众多云服务商和模型提供商支持通过API调用LLM,用户只需简单配置即可运行复杂的MMLU测试。选择合适的模型和端点,成为评测成功的关键。值得一提的是,部分平台还提供了加速版本的MMLU-Light评测,能够大幅缩短测试时间并节约计算资源,适合快速迭代和大规模对比。
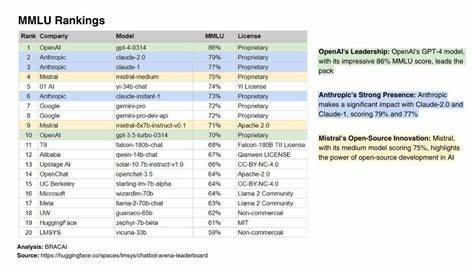
以目前测试成果为例,基于Llama-4-Scout-17B-16E-Instruct-FP8模型的测试在api.llama.com端点取得了高达84.8%的优异成绩,充分展现了该模型在多任务理解中的强大实力。与此同时,Llama-3.3-70B-Instruct(Light)和Gemma-3-27b-it(Light)在各自平台的表现也均在80%左右,显示出不同架构和规模模型的多样化优势。通过这些数据,用户可以直观感受到各模型在综合任务上的差异,帮助其做出更加精准的应用部署方案。此外,不同平台的访问机制也为用户带来诸多便利。无论是Borg Cloud、OpenAI、Google AI Studio、LLaMA.com还是OpenRouter,用户只需输入相应的模型名称和访问令牌,即可开始测试,快速获得详尽的性能反馈。更进一步,公开的模型测试结果持续更新,为整个AI社区提供了丰富的参考数据和趋势分析。
对开发者来说,通过云端API轻松运行标准化的MMLU测试,不仅能节省本地计算资源,还能批量对比不同模型版本、调整参数方案,显著提升研发效率。作为行业标杆,MMLU的广泛部署也促进了AI技术的透明度和公平竞争,推动模型开发者不断优化训练策略和算法创新。展望未来,随着AI模型规模的不断扩大和应用场景的日益复杂,基准测试工具如MMLU将在评估体系中扮演更加关键的角色。结合自动化测试平台和智能数据分析能力,开发者将能够实时诊断模型性能瓶颈,精细调整模型结构,持续提升语言理解和生成能力。无论是企业还是科研机构,都可以借助这一开放工具链,快速验证和验证其AI产品的综合性能,确保模型在实际业务中的稳健性和高效性。整体而言,通过在不同大型语言模型API端点上运行MMLU基准测试,行业正在形成一个开放、互通、高效的生态环境。
借助持续完善的评测数据和便捷的操作流程,用户能够实现模型选择的科学化和优化过程的自动化。随着技术的进步,更多轻量化、高性能的评测版本将不断涌现,推动整个AI领域迈向更加智能和普惠的未来。