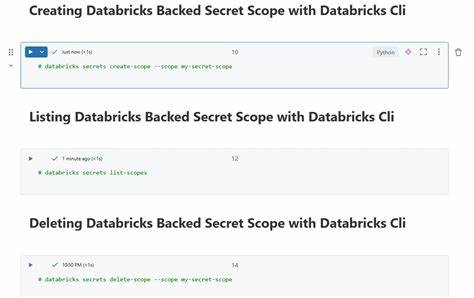
在当今数字经济时代,数据已成为企业最宝贵的资产。然而,数据质量问题普遍存在,尤其是在大规模数据环境下,无效数据的存在严重影响了数据分析的准确性和业务决策的可靠性。为此,业界不断寻求更智能、更高效的数据质量保障方案。在这其中,Databricks Labs开发的DQX数据质量框架凭借其创新的无效数据隔离(Quarantining Invalid Data)方法,成为行业关注的焦点。DQX不仅实现了自动化的数据质量检测,还支持基于规则的智能数据剖析和多维度数据质量管理。DQX的核心在于利用先进的程序化数据剖析能力,结合灵活的质量规则生成机制,有效隔离并管理数据中的异常和无效部分,保障下游数据流程的纯净和可信。
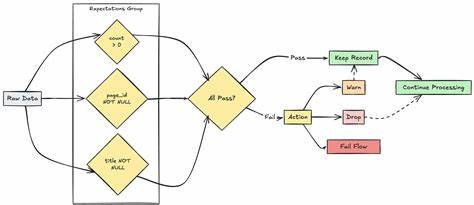
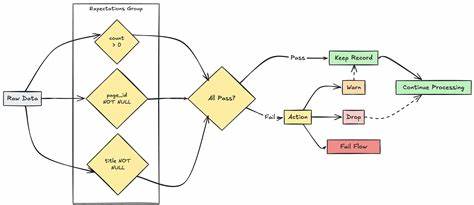
DQX采用了基于Spark数据框架的分析引擎,利用DQProfiler类进行全方位的数据剖析。该组件通过对输入数据帧的逐列分析,提取统计摘要和潜在的质量规则候选,形成有效的质量检测策略。它支持多种灵活配置选项,包括采样率控制、异常值检测、多线程表级并行处理等,以适应不同场景的复杂需求。DQProfiler类不仅支持单表数据剖析,还能通过pattern匹配实现多表同时分析,大幅提升数据检测的效率。数据质量规则(DQProfile)通过剖析得到的统计特征自动生成。规则涵盖了数据为非空、取值范围约束、特定枚举值限制、字符串非空等多种类型。
系统支持对不同数据类型进行针对性规则生成,如字符串类支持去空字符和空值检测,数值类支持最小最大值约束和异常值剔除,时间类型数据支持日期范围校验等。异常值识别是其中的核心功能之一。DQX采用基于统计学的方法,利用标准差范围对极端值进行自动排查,可选配置允许用户灵活调整检测灵敏度。生成的各类规则通过统一接口导出,方便与后续的质量检查引擎DQEngine以及数据管道集成。与此同时,DQX提供了深度的集成支持,包括与湖仓统一的Lakeflow流水线、dbt工具链以及Databricks的资产包系统,帮助企业快速搭建自动化的数据质量治理平台。除此之外,DQX框架支持基于模式的执行管理与动态质量检查,实现了工作流自动化和任务编排能力的创新。
DQX的设计充分考虑了复杂数据结构,如嵌套结构体(StructType)的扁平化处理,确保了对复杂架构数据的全面覆盖和细致检验。相较于传统数据质量检测方法,DQX在性能和扩展性方面表现卓越。它通过多线程并行处理多表数据,结合智能的选项匹配和优先级排序,实现了高效、精准的质量剖析和规则生成。这种架构适配云原生环境,保障了大规模业务场景下的稳定运维与弹性扩展。在实施过程中,DQX还提供了丰富的API支持和命令行工具,方便开发人员和数据工程师调用和集成。其基于Python和Spark生态的实现使得系统易于扩展和维护。
为了满足业务快速变化的需求,DQX支持自定义质量检查函数,允许用户根据实际业务规则增添特定的检测逻辑。随着人工智能技术的渗透,DQX也引入了AI辅助规则生成,通过分析数据分布和异常模式,智能推荐最优的质量检测规则,显著提高检测的覆盖率和效率。数据隔离(Quarantining Invalid Data)机制是DQX的一大创新亮点。通过自动检测出无效、异常或不合规的数据条目,系统将这些数据自动隔离保存,防止其影响正常业务流程和分析模型。隔离的数据还可以供数据工程师进一步审查、校正或删除,提升数据治理闭环的完整性。这种机制不仅提高了数据的可信度,还有效降低了因数据缺陷导致的业务风险。
未来,随着数据量和类型的不断多样化,数据质量管理的难度只会加大。DQX的数据隔离和自动化质量检测技术正好满足了这一趋势,通过在数据入湖和处理前设置多层次自动检测,协助企业实时捕获和治理数据问题,构建高质量可信数据资产库。综上所述,Databricks Labs的DQX框架以其前瞻性的程序化数据剖析、灵活的规则生成和强大的无效数据隔离功能,为现代企业的数据质量管理开辟了新的路径。它不仅提升了数据治理的效率和自动化水平,还保障了核心业务数据的安全性与准确性。数据驱动的未来离不开高质量的数据基础,DQX为数据治理注入了创新的动力,推动企业数字智能转型迈向更高水平。随着越来越多的企业意识到数据质量的重要性,DQX的应用价值将持续被挖掘和放大,成为数据质量管理领域的标杆产品和解决方案。
。