在大数据时代,数据质量已然成为企业竞争力的核心组成部分。无论是数据分析还是机器学习,依赖的都是高质量、准确无误的底层数据。数据存在格式不一致、缺失值、重复记录或者过时信息时,很可能导致误导性的分析结果,影响决策质量,甚至造成经济损失。Databricks作为基于Apache Spark打造的统一数据分析平台,不仅支持高效的数据处理和分析,还为数据团队提供协作环境,极大提升工作效率。为了解决数据质量频发的挑战,Databricks Labs推出了DQX(Data Quality Expectations)框架,使得用户能够在Databricks环境内轻松定义、验证和执行数据质量规则。DQX不仅帮助管理大规模数据流水线,还能在模型优化中确保数据的完整和准确。
首先,安装DQX非常简便,只需在Databricks环境中通过pip命令完成安装,并重启Python环境即可,这让数据团队能够快速集成数据质量检查流程到已有分析架构中。接下来,数据加载和探查是关键一步。通过加载数据集到Spark DataFrame后,用户可以使用DQProfiler对数据进行深入分析,从结构、数据类型到缺失值比例,生成详细的数据统计摘要和分析报告。这些信息不仅帮助识别潜在数据问题,也为后续规则制定提供坚实依据。值得关注的是,DQX能够自动基于数据探查结果生成针对性的质量规则。例如,对于关键字段要求非空约束,对于数值型数据设定上下限范围,对于类别字段限定合法取值列表,都能实现自动化的规则创建并存储为易管理的YAML或JSON文件,有效提升了管理效率。
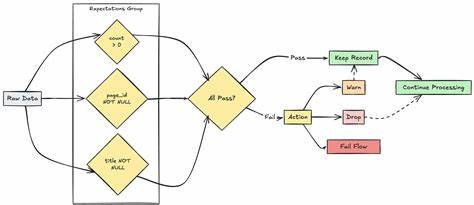
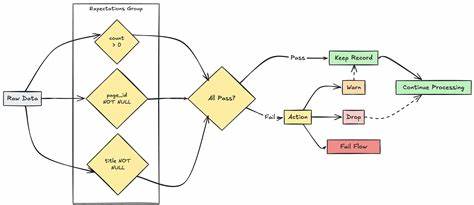
规则生成后,通过DQEngine引擎即可将其应用于数据处理流程中,完成规则验证和数据分割。通过检查结果区分合格数据和需质控的异常数据,为后续数据标准化或清洗提供便利。对于不同程度的数据异常,DQX还支持设定不同的"严重性等级",例如"错误"级别的异常将阻断数据流,送入隔离区;"警告"级别则允许数据继续流转,同时发出提醒,帮助企业细分和控制风险。除了内置规则,DQX还允许用户自定义检查函数,结合SQL表达式或Python脚本对特定业务场景实行专属验证,诸如邮箱格式校验,用户年龄限制等。这样极大地增强了数据校验的灵活性,满足不同业务对数据规范的多样需求。在规则管理上,DQX还支持代码化定义,使得规则不仅可以通过YAML配置维护,也能以代码形式动态生成和执行,便于版本控制与自动化集成。
此外,针对不同的检查场景,用户可以灵活选择多种加载规则的途径:无论是安装包内置的规则文件、Databricks工作区文件、还是本地文件系统甚至Azure数据湖中的规则,都能无缝接入并执行,确保规则管理的便捷与统一。总结来看,Databricks DQX通过实现自动化、可扩展的数据质量管理,帮助企业建立了数据治理的坚实基础,保证了数据在进入分析和机器学习阶段前的准确性和完整性。对数据工程师而言,DQX不仅是降低人工维护成本的工具,更是一条通向数据驱动智能决策和创新的捷径。随着数据规模和复杂度的提升,采用像DQX这样的现代数据质量框架,将成为推动企业数字化转型和智能升级不可或缺的重要环节。 。