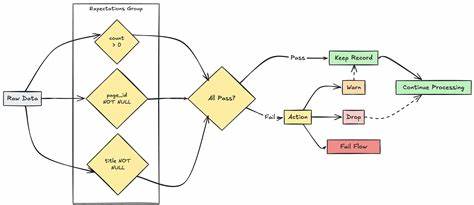
随着大数据和云计算技术的飞速发展,数据的有效管理和高质量保证成为企业数字化转型的重要基础。Azure Databricks作为综合数据分析平台提供了强大的Lakeflow Spark声明式管道功能,其中的管道期望(Expectations)为数据质量管理开辟了全新的路径,使用户能够在数据流经ETL(抽取、转换、加载)管道时,实时验证数据的准确性和可靠性。期望机制不仅能够提前发现和处理异常数据,还帮助企业实现自动化审计和监管,确保数据资产的健康和价值最大化。管道期望是什么?简单来说,期望是嵌入在管道创建语句中的可选条件,用来对每条经过数据记录施加约束,这些约束通过标准SQL布尔表达式定义,清晰判定数据是否满足业务规则。每条期望都有唯一的名称,便于监控和统计分析。期望允许多条并行定义,灵活覆盖数据集的各类质量维度,提升管道的透明度和可维护性。
在定义期望时,用户可以灵活采用SQL语句或者Python注解方式,通过constraint(约束)表达各种业务逻辑,从价格的非负数、日期的合理范围,到复杂的订单状态验证等,均可实现自动化校验。需要注意的是,约束表达式必须符合SQL规范,不支持引用外部函数或服务调用,确保执行效率和安全性。对于不合规数据的处理,Azure Databricks管道期望提供了三种操作策略:warn、drop和fail。warn是默认行为,允许不合格数据继续写入目标,但记录相关信息供后续分析;drop策略则会在写入目标前剔除不符合要求的记录,并统计日志;fail策略更加严格,一旦检测到违规记录,整个数据更新操作会立即回滚并提示错误,需要人工干预解决,这种机制有助于保障数据质量的零容忍。系统还提供了方便的指标追踪功能,用户可以在Databricks的管道UI界面中查看每个数据集对应的期望执行情况与质量指标,通过直观的可视化图表,及时发现问题所在。此外,期望违背的详细提示信息,包括输入输出数据样本,都有助于快速定位异常数据源和根因分析,极大提升数据运维效率。
当面对复杂项目时,Azure Databricks的期望还支持将多条期望合并为一组,通过expect_all、expect_all_or_drop、expect_all_or_fail等方法统一管理,简化开发流程,而期望的复用性设计使同一套校验规则能够跨多个数据集共享,促使企业级数据质量规范标准化。虽然期望功能功能强大,但目前仅限于流式表和物化视图类型,对某些操作和场景仍有局限性,使用时需结合具体业务需求和数据架构设计合理运用。通过对数据中不合格记录的保留、剔除或失败回滚,企业不仅能有效提升管道数据的可信度,还能更深入理解数据变化规律和异常模式,推动数据文化的建设和数据驱动决策。结合Azure Databricks独特的Lakeflow Spark声明式管道架构,构建基于期望的质量管理体系,可帮助组织实现更安全、透明且高效的现代数据管道,为各类数据分析、机器学习及商业智能应用提供坚实的数据基础。总之,随着数据规模和复杂性的不断增加,依赖手工和事后清洗的数据质量管理方式已难以胜任,借助Azure Databricks的管道期望功能,企业能够主动、自动地在数据生产线上检测和管理数据质量,显著降低风险,提高数据资产价值。在未来的数字化转型旅程中,高效的数据质量保障方案将成为企业保持竞争优势的关键,而Azure Databricks的管道期望正是实现这一目标的重要利器。
。