在当今数字化时代,数据已成为企业最宝贵的资源。高质量的数据不仅是有效决策的基础,更是推动业务创新与增长的关键。Databricks作为领先的大数据分析平台,为企业提供了一整套强大的工具与技术,帮助用户管理海量数据,实现数据的清洗、整合和分析。然而,如何确保数据的质量,从而发挥数据的最大价值,是许多企业和数据科学家面临的重大挑战。本文将深入探讨Databricks专家们分享的秘密数据质量提升技巧,揭示如何通过优化数据管道和应用先进技术,实现数据质量监控和保障。首先,数据质量的重要性不可忽视。
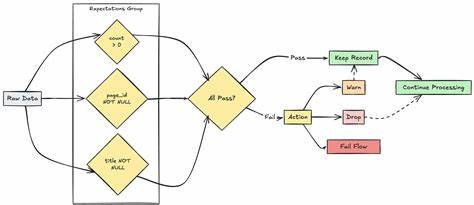
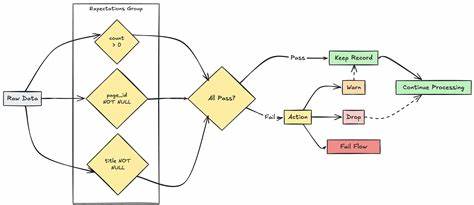
无论是错误数据、缺失值还是重复信息,都可能导致分析结果偏差,影响业务判断。Databricks平台通过强大的Spark引擎支持大规模数据处理,结合其丰富的生态系统,能够有效应对数据质量问题。专家指出,确保数据质量的首要步骤是建立全面的数据质量监控体系。Databricks内置的Data Quality功能允许用户实时检测数据中的异常和缺陷。借助自动化规则,系统可以识别数据范围、格式、唯一性及完整性等问题,及时反馈并触发警报,确保数据管道中的每一步都符合预定标准。除了基础的监控,构建灵活的数据验证规则至关重要。
专家建议结合业务需求设计多层次的数据校验策略,既包括基本的结构化校验,如字段类型和非空约束,也涵盖高级校验,比如跨数据集的一致性检验和时序数据的趋势分析。通过数据需求文档与质量规则库的管理,团队可以持续优化验证逻辑,适应业务变化。数据清洗是提升质量不可或缺的一环。借助Databricks强大的数据转换能力,专家们推荐采用增量清洗策略,针对新导入数据进行实时或批处理操作,有效剔除脏数据和异常值。通过与Delta Lake结合,利用事务日志和版本控制,确保数据变更的可追溯性和恢复性,为数据质量审核提供可靠保障。此外,专家还强调了构建可重复的数据质量测试流程的重要性。
通过集成持续集成和持续部署(CI/CD)流水线,自动执行数据质量检查,提高数据代码的稳定性和可维护性。Databricks的Notebook与工作流管理工具为团队协作提供了极大便利,有助于快速定位并解决潜在数据问题。面对多样化数据源和复杂的数据形态,专家建议采用机器学习技术辅助识别数据异常。例如利用无监督学习模型监控数据分布变化,及早发现潜在数据漂移,降低质量风险。同时,结合注释数据和规则引擎,实现数据异常自动分类与处理,极大提升运营效率。数据治理与合规性同样是数据质量管理的重要方面。
Databricks提供完善的访问控制和审计日志功能,确保数据使用过程的安全与合规。专家提倡在数据质量管理框架中融入治理理念,将数据质量指标与KPI挂钩,形成闭环管理,促进整体数据资产的价值提升。最后,专家提醒,数据质量的提升是一个持续不断的过程,需要跨部门协作和技术手段的结合。通过持续优化数据工艺,同时加强人员培训与文化建设,企业能建立起高效稳健的数据质量管理体系,助力数字化转型与智能决策。综上所述,Databricks专家揭示的诸多秘密技巧,为企业打造优质数据基础提供了宝贵参考。借助数据质量监控、灵活校验、智能清洗以及自动化测试等方法,结合先进的机器学习与治理策略,企业能显著提升数据的准确性和可靠性,从而释放数据的真正价值。
未来,随着数据量的不断增长与分析需求的提升,持续改进数据质量管理将成为企业保持竞争优势的关键所在。 。