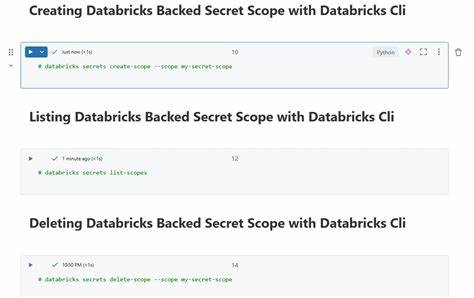
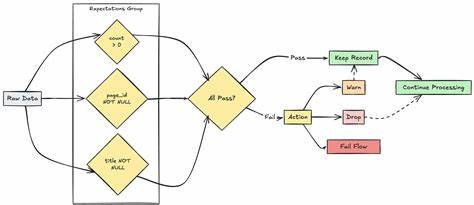
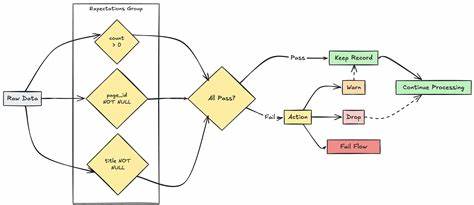
随着大数据和人工智能的快速发展,数据质量的重要性日益凸显。Azure Databricks作为微软云平台上领先的统一数据分析服务,其强大的数据处理和分析能力广受青睐。而在海量数据流入和不断更新的现代数据平台中,如何确保数据的准确性、完整性和规范性,成为每个数据工程师亟待解决的难题。Azure Databricks针对这一挑战,推出了期望(Expectations)机制,通过在数据管道中显式声明数据质量约束,帮助用户实现数据质量监控与保障。期望机制核心依赖Python的装饰器语法,借助于Databricks Pipelines(dp模块)实现灵活而高效的数据质量约束定义。核心思想是将数据质量规则作为装饰器附加到具体的数据集定义函数上,不论是物化视图(materialized views)、流式表(streaming tables)还是临时视图(temporary views),都能采用期望机制进行验证。
这些期望装饰器通过接收描述(description)及具体的SQL条件约束(constraint),以声明的形式对单条或多条数据记录进行合规性检测,确保生成的数据符合预设标准。Azure Databricks提供了多种期望装饰器选项以适应不同的应用场景和数据质量策略。其中最基础的是@dp.expect装饰器,它基于单一的规则对数据进行验证,只要记录满足条件就被视为合格。更具灵活性的是三种行为控制级别的期望装饰器,分别是@dp.expect、@dp.expect_or_drop和@dp.expect_or_fail。@dp.expect允许违规数据依然保留在目标数据集中,但会在统计中记录合法与非法数据的数量,适合宽容型数据质量检查。@dp.expect_or_drop会在写入目标数据之前剔除不符合要求的记录,从而保证最终数据集无违规数据。
@dp.expect_or_fail则采取最严格的策略,一旦检测到问题即刻停止当前数据流的更新,但不会影响管道中其他独立数据流的运行,这有助于快速发现并阻断严重的数据质量异常。此外,针对复杂数据质量场景,Azure Databricks支持在单个装饰器中定义多个期望条件,使用@dp.expect_all系列装饰器如@dp.expect_all、@dp.expect_all_or_drop及@dp.expect_all_or_fail,允许用户同时声明多项数据质量约束,每项都有独立的描述和监控指标,细化并丰富了数据质量的监控维度。这种多重约束机制极大增强了数据验证的严谨性和透明度。语法层面,期望装饰器必须置于数据集定义装饰器(如@dp.table、@dp.materialized_view或@dp.temporary_view)之后,在Python函数定义之前。用户只需通过SQL表达式描述每一个数据质量约束,该表达式针对每条记录的布尔判断结果决定该条记录是否违规。例如,可以编写约束语句确保某字段不为空,数值在合理范围内,或者文本符合特定格式。
通过这种编程模型,数据工程师能够在ETL流程的设计阶段即嵌入强有力的质量保障逻辑,实现数据从源头到目标的全链路管控。在实际应用中,期望装饰器的指标记录功能极具价值。无论是保留违规数据还是剔除升级,系统均会自动统计各类数据状态,生成详尽的质量报告,为后续的数据监控和优化提供充足依据。结合Databricks工作区的可视化仪表盘,企业决策者和运维人员能够实时掌握数据质量动态,迅速定位问题数据源,有效减少数据异常带来的业务风险。Azure Databricks的期望机制不仅仅提升了数据质量保障手段,更赋予数据管道开发过程更高的灵活性和效率。开发者可以根据业务需求自定义适合的质量策略,在保证数据安全与合规的同时,平衡性能和资源消耗,满足不同环境下的数据处理需求。
通过采用标准化、声明式的数据质量约束,团队协作也变得更加顺畅,避免了传统代码中隐含逻辑的重复开发和理解误差。展望未来,随着云计算与人工智能的深度融合,数据治理和质量管理将成为推动数字转型的核心支柱。Azure Databricks的期望机制紧密结合现代数据工程的最佳实践,为云原生数据平台注入了智能、安全和自动化的基因。掌握并善用期望功能,将助力企业构建高质量、可追溯且高效的数据生态体系,为分析洞察和智能决策提供坚实基础。在Azure Databricks生态中,正确配置和利用期望装饰器,是确保数据管道稳定、数据资产可信的关键所在。面对复杂多变的业务需求,数据质量不能再被视作事后补救,而应前置于整个数据生命周期。
借助Azure Databricks提供的丰富工具,用户能够实现数据质量的全流程自动管理,避免脏数据流入分析模型,从根本上提升数据驱动业务的成功率。总结而言,Azure Databricks中的期望机制是一种强大且灵活的数据质量控制方案,紧密结合Pipeline架构和Spark计算平台特性,赋能数据团队高效开发并精准把控数据质量。它支持多种严格程度的策略选择,满足从宽容到严格不同场景需求,帮助企业在面对数据洪流时依然能够保持清晰、可信和可用的数据信息。在大数据驱动的时代,掌握并精通此机制,将成为数据驱动型企业在竞争中脱颖而出的重要利器。 。