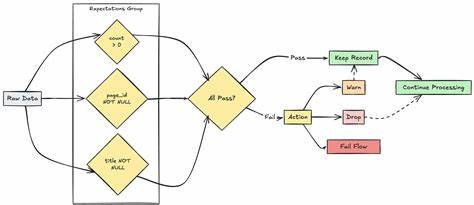
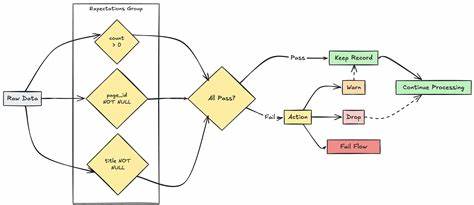
在当今数据驱动的时代,数据质量成为企业成功的核心要素之一。随着大数据技术的普及,尤其是Apache Spark和其Python API PySpark的广泛应用,如何确保数据的准确性、完整性和一致性成为数据工程师和数据科学家的重要课题。针对这一需求,Databricks Labs推出了开源项目DQX(Data Quality eXperience),为PySpark数据框架提供了一套功能强大且易用的数据质量验证工具。DQX不仅支持批量数据处理,也兼顾流式数据的质量检测,凭借其灵活性和高效性,正逐步成为数据质量管理领域的利器。 DQX框架基于Databricks和Apache Spark生态系统,旨在帮助用户简化复杂数据质量检查过程。其核心设计理念是模块化构建和策略驱动,用户可以定义多种数据质量规则,自动化执行验证任务,并生成详尽的质量报告。
通过这种方式,DQX极大降低了人工干预成本,提高了数据处理的可信度与时效性。无论是在数据湖、数据仓库还是湖仓结合的架构环境中,DQX均表现出优异的兼容性和适配能力。 DQX的优势首先体现在其支持丰富的数据质量规则,包括唯一性检测、非空检查、范围验证、模式匹配等多种常见且关键的验证手段。基于PySpark强大的分布式计算能力,DQX能够在大规模数据集上快速执行规则校验,确保即使在千万级、亿级数据行环境下,也能保持高效的运行性能。特别对于不断变化的流数据,DQX能够实时监控数据质量,帮助企业及时发现异常,避免后续业务决策因数据缺陷导致的风险。 此外,DQX框架还具备强大的配置管理功能。
用户可以通过简单的JSON或YAML配置文件定义质量检查规则和阈值,无需深入代码实现即能灵活调整验证策略。这种设计不仅提升了用户体验,也方便了持续集成和自动化部署,使数据质量管理更具有持续性和可重复性。结合Databricks平台的强大算力和自动化运维特性,DQX能够无缝融入现有数据流水线,实现端到端的质量保证。 文档和社区支持方面,DQX项目维护者提供了详尽的在线文档,涵盖安装指南、使用示例、规则定义以及常见疑难解答。丰富的教程案例帮助开发者快速上手,迅速掌握数据质量规则的编写和调试技巧。同时,该项目活跃的GitHub社区也促成了持续的功能迭代和问题修复,新版本频繁发布以响应用户反馈并适应新技术需求。
值得注意的是,DQX虽然由Databricks Labs开发,但作为开源项目,目前官方不承诺SLAs支持,用户应当根据自身需求判断使用方式。 实战应用层面,许多企业已经在生产环境中采用DQX来保障数据管道的健康运行。通过集成DQX,数据团队可以设立自动化阈值告警,当数据异常触发时及时通知相关人员,减少数据质量问题对下游分析和模型训练的影响。例如在金融行业中,准确的客户信息和交易数据对风险控制至关重要,DQX帮助实现全面的质量监控,提升了数据治理的规范性和透明度。另外,在电商、医疗、制造等领域,利用DQX对数据完整性和时效性进行严格校验,也极大促进了业务流程的优化和效率提升。 总结来看,DQX作为Databricks Labs开源的PySpark数据质量验证框架,提供了切实可行的解决方案来应对大规模数据环境下的质量管理难题。
它结合了高性能计算、灵活规则配置和全面的监控能力,极大提升了数据团队的工作效率和数据资产的价值挖掘潜力。随着数据规模和复杂度的不断增加,采用像DQX这样的先进工具实现数据质量自动化管理,已成为保障数据驱动业务持续健康发展的关键举措。未来,随着社区的不断发展和功能完善,DQX有望在数据工程领域扮演更加重要的角色,助力更多企业迈向智能化转型的新高度。 。