在数字化转型浪潮的推动下,企业对数据质量的要求越来越高,优质的数据成为决策支持和业务创新的基石。然而,如何确保数据在规模庞大且复杂的环境中保持高质量,却是一项充满挑战的任务。Databricks作为领先的湖仓一体化平台,以其独特的架构优势和丰富的数据管理功能,成为现代企业实现数据质量管理的强大引擎。 数据质量究竟为何如此关键?在现实业务中,数据错误或无效数据不仅会误导决策者,还可能导致监管合规风险和商业机会的流失。据Gartner统计,数据质量问题平均每年给企业带来高达1,290万美元的损失。面对这种情况,企业迫切需要一套涵盖人、流程与技术的集成方案,确保数据全生命周期的高质量保障。
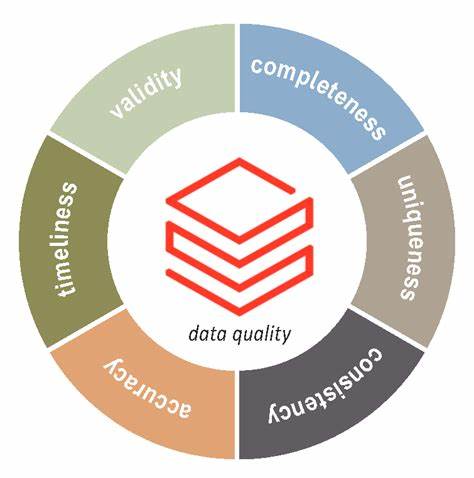
理解数据质量的本质,必须深入认识其六大核心维度,包括一致性、准确性、有效性、完整性、及时性和唯一性。这些维度相辅相成,共同构成了数据健康的基石。首先,一致性要求数据在不同系统和数据集之间不产生冲突,确保所有用户获取相同的真相视图。准确性强调数据必须真实反映业务事实,无误差存在。有效性则关注数据格式和规则的合规,防止无效数据进入系统。完整性确保所有必要数据都被收集和存储,以支持全面分析。
及时性则考量数据从生成到可用之间的时延,满足业务的实时需求。最后,唯一性防止重复数据,以免影响统计结果和业务判断。 Databricks的湖仓平台通过融合数据湖与数据仓库的优势,打破了以往系统孤岛的问题,所有数据和工作负载都集中统一管理。其旗舰的三层Medallion架构为数据清洗和转化提供了清晰路径。最初数据在Bronze层以原始未处理状态入湖,以完整保存所有细节;在Silver层进行数据校验和清洗,包括去重、字段校验等操作,成为事实数据的单一来源;Gold层则负责为最终用户呈现聚合且精炼的数据视角,支持报告和分析应用。 为了维护一致性,Databricks依托ACID兼容的Delta Lake技术,利用乐观并发控制保证数据读写的事务安全,避免并发冲突。
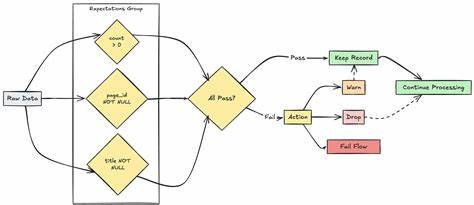
通过事务的读-写-验证提交步骤,确保每次操作都是原子性的,彻底杜绝数据版本的冲突和脏读。相比传统Parquet表,Delta Lake的版本化和事务特性大幅提升了数据稳定性和一致性。 准确性保障着重于防止错误数据入库,Databricks支持通过表约束(NOT NULL、CHECK)和COPY INTO命令中的数据校验功能,预先检验数据合法性,阻止违背规则的数据写入。此外,Lakeflow Spark声明式流水线集成的数据质量期待机制,允许用户定义丰富的校验规则,实时标注或隔离异常记录。结合数据隔离(隔离区)功能,坏数据可被存放于单独表或文件路径,便于后续复核和修正,保证主数据的纯净性。 数据的有效性在广播层面的保障同样重要。
Delta Lake内置的模式强制(Schema Enforcement)防止数据结构不匹配的写入错误,模式进化(Schema Evolution)可以自动适应新增字段变化,亲和不断演化的业务场景。同时,自动加载器(Auto Loader)通过智能模式推断和演进管理,简化了流式和分批入湖作业,避免数据模式冲突引发的异常。 针对完整性,Databricks充分利用云端存储的弹性扩展性能,可以稳定支持海量数据的采集和持久化,降低了因存储瓶颈导致数据缺失的风险。其ACID事务保证数据写操作要么全成功,要么全失败,无部分写入,杜绝因中间错误导致数据不完整的现象。此外,数据丰富(Enrichment)机制能够记录时间戳和数据来源文件名,提升数据追溯和审计的能力,辅助分析问题根源。 及时性是当今数据驱动业务竞争中至关重要的一环。
得益于Delta Lake对高并发写入的支持,Databricks允许多个数据流和任务并行无阻塞更新数据。结构化流(Structured Streaming)和Lakeflow Spark声明式管道让企业能从批量处理轻松转向近实时处理架构,加快数据从系统生成到分析呈现的速度,大幅提升业务响应能力。 唯一性则通过多种去重工具保障。无论是基于合并写入(MERGE)的事务性更新,还是基于distinct()和dropDuplicates()等API实现的查重去重,亦或是利用窗口函数结合排序规则筛选最新记录的复杂去重逻辑,Databricks均提供灵活且高效的去重策略,确保数据不出现重复条目,维护分析结果的准确性。 为了让数据质量管理进一步可视化和自动化,Databricks还推出了湖仓监控(Lakehouse Monitoring)服务。该服务利用人工智能技术,自动生成覆盖时间序列、快照以及模型推断等多维度的质量指标仪表盘,支持多姿态的数据质量分析。
用户可以借助Databricks SQL快速搭建自定义监控视图,并设定告警,实时捕捉异常波动。此外,数据血缘(Unity Catalog)与监控集成使得问题溯源变得高效且准确。 总而言之,Databricks通过深度整合数据湖与数据仓库能力,利用Delta Lake的事务保障、湖仓监控平台和Lakeflow Spark声明式流水线,构筑了全面、灵活且高度自动化的数据质量管理体系。无论是对数据完整性、准确性的守护,还是对数据及时性和一致性需求的满足,都展现出强大的技术优势和商业价值。对于希望在大数据时代提升数据资产价值,实现数据驱动决策的企业而言,Databricks无疑是值得信赖的优选方案。 未来,随着数据量和数据种类的不断增长,数据质量管理将愈发复杂。
Databricks计划持续深化AI赋能的自动检测和自适应告警功能,进一步减轻人工干预负担,实现更为智能和主动的数据治理。拥抱这样一套融合创新技术与实践经验的现代化数据质量管理体系,将助力企业在激烈的市场竞争中抢占先机,驱动业务持续增长与创新。 。