随着人工智能技术的不断进步,语言模型在自然语言处理领域中扮演着越来越重要的角色。近年来,研究者们不断探索提升模型性能和效率的新路径,以满足日益多样化的应用需求。Falcon-H1系列语言模型正是在这一背景下应运而生,通过引入创新的混合架构设计,重新定义了大规模语言模型的效率和表现。Falcon-H1不仅在模型设计上实现突破,还在训练方法和数据策略方面展现出卓越的优势,成为业界关注的焦点。 Falcon-H1系列模型的最大亮点在于其独特的混合头(Hybrid-Head)架构。这种设计巧妙地结合了Transformer架构的自注意力机制和状态空间模型(State Space Models, SSMs)的长距离依赖处理能力,弥补了传统Transformer模型在长文本上下文处理中的不足。
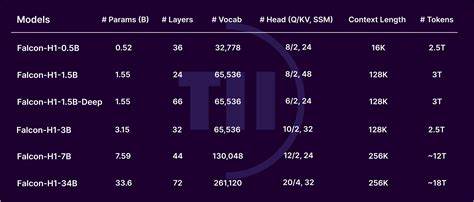
SSMs因其出色的记忆保存能力和计算效率而被广泛看好,特别适合需要处理超大上下文窗口的任务。通过将两者并行运行,Falcon-H1不仅能够保持Transformer模型在捕捉局部语义细节方面的优势,还能够充分发挥SSMs在处理长序列时的高效性。 Falcon-H1的多配置版本覆盖了从小型到超大规模的模型参数区间,包括0.5亿、1.5亿、3亿、7亿及达到340亿参数的旗舰版本,满足不同规模和复杂度任务的需求。值得注意的是,部分版本还进行了指令微调(Instruction-Tuning),使模型在理解并执行用户指令时表现更加出色。这种灵活多样的模型阵容为开发者和研究人员提供了更多选择空间,既能快速部署轻量级应用,又能支持复杂的多领域任务。 训练Falcon-H1模型的团队在数据策略上同样做了深入探索。
通过精心挑选和处理多样、优质的大规模语料,同时引入多语言和多任务训练目标,确保模型具备丰富的知识储备和强大的泛化能力。训练动态方面,研究者针对每个模型大小进行了优化,采用先进的正则化技术和学习率调度策略,有效提升了模型的稳定性和训练效率。此外,训练过程强调兼顾计算资源的高效利用,降低了能耗和成本。 在性能表现方面,Falcon-H1系列取得了令人瞩目的成绩。旗舰版本Falcon-H1-34B在多个权威基准测试中显示出超越同参数规模甚至远超其他业界领先模型的实力,比如在推理能力、数学计算、多语种理解和科学知识问答等方面均表现抢眼。它不仅与一些70亿至百亿参数量级的模型分庭抗礼,而是以更少的参数和训练数据达到甚至超过这些大型模型的水平。
这种性能与效率的双重突破,使得Falcon-H1在实际应用中具备了极高的性价比。 较小型号的Falcon-H1模型同样表现突出。例如,1.5亿参数版本的“Deep”模型在许多测试中能够媲美7亿至10亿参数的传统模型,充分展示了混合头架构下的小规模模型也能保持优异性能。0.5亿参数的模型更是在2024年发布的同类7亿参数模型面前表现出色,这对资源受限的场景尤为重要,拓宽了语言模型的应用边界。 Falcon-H1系列模型还支持超长上下文输入,最高可达256000个上下文标记,这在当前行业中处于领先水平,使得模型能够处理极其复杂且信息量巨大的文档,为法律、科研、金融等领域的深度文本分析提供强大支持。同时,模型涵盖了18种语言,满足全球不同语种用户的需求,展现了极强的多语言泛化能力,推动了跨语言自然语言处理技术的发展。
值得一提的是,Falcon-H1的发布秉持开源和开放的原则,所有模型均以宽松的开源许可形式提供,方便开发者自由使用和二次开发。这种开放策略有助于推动学术界和工业界的广泛合作,加速创新步伐。模型在Hugging Face Hub上提供了超过30个版本的预训练和微调模型,极大方便了社区用户的下载和集成应用。 从整体来看,Falcon-H1不仅体现了设计创新和工程实践的高度融合,还代表了大规模语言模型未来发展的重要趋势。混合头架构的引入为解决Transformer在长文本理解和计算效率瓶颈提供了可行路径,同时在保证模型性能的前提下,大幅提升了资源利用率和训练速度。Falcon-H1的成功经验将激励更多研究团队探索类似混合模式,推动语言模型技术的多样化和专业化发展。
面对日益复杂和多元化的自然语言处理需求,Falcon-H1系列通过技术创新展现了应对挑战的强大实力。无论是应用于智能问答、文本生成、机器翻译,还是多领域知识挖掘,Falcon-H1都表现出卓越的适应能力和广泛的应用潜力。其开创性的混合头设计和优秀的性能指标为行业树立了新的标杆,成为未来智能语言模型发展的重要里程碑。 随着人工智能领域不断迈向更高水平,对模型性能和效率的需求也会持续升级。Falcon-H1系列无疑为自然语言理解和生成技术提供了宝贵的参考范式,推动了AI向更加智能、高效和人性化方向发展。科技界和产业界的持续关注和应用实践,将进一步挖掘此类混合架构模型的潜力,助力实现智能化时代的更多可能性。
。