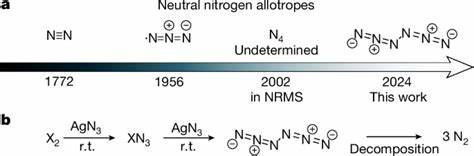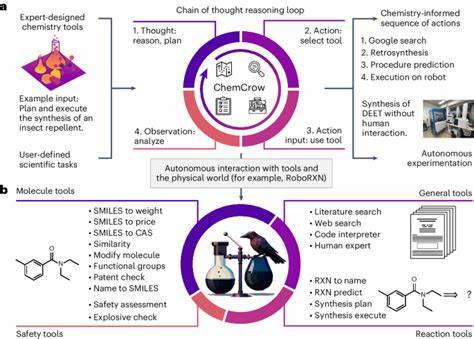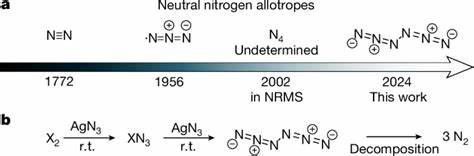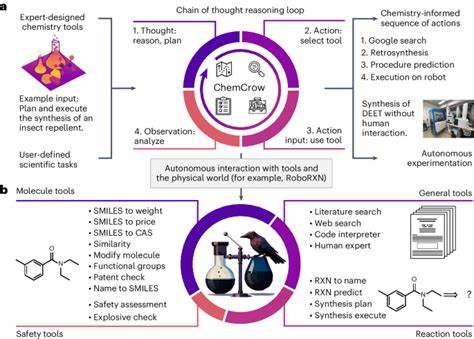
随着人工智能技术的迅猛发展,大型语言模型(LLMs)在各个领域的应用越来越广泛,化学领域也不例外。作为利用海量文本数据训练而成的模型,这些语言模型展示出了强大的语言处理能力,甚至可以完成未被明确训练过的任务。近年来,科学界开始关注它们在化学知识理解与推理方面的表现,与传统的人类化学专家形成了令人兴奋的对比与探讨。 大型语言模型如GPT-4和其他顶尖系统依赖于深度学习和大规模语料库,通过文本预测学习化学相关知识和技能。它们不仅能回答基础的化学问题,还能够应对更复杂的推理任务,像设计化学反应和预测分子性质等,甚至在某些测试中表现出超过部分人类专家的能力。这种现象激发了人们对人工智能是否能在化学研究中担当“助手”甚至“同行”角色的期待。
然而,虽然大型语言模型表现出令人瞩目的能力,但它们在处理化学问题时依然存在显著的局限性。首先,模型在回答需要深入理解和复杂推理的知识密集型问题时表现不佳,难以实现对关键事实的准确记忆。其次,它们往往对自身输出过于自信,缺乏有效的内在信心评估机制,导致错误答案潜在的误导风险。此外,部分涉及实验安全、毒性与合规性的题目,模型的回答准确率较低,这对实际应用构成严峻挑战。 针对这一现状,科研团队开发了ChemBench这一评估框架,涵盖近2800个多元化的化学问答对,涵盖了从基础化学到专业分支的各类主题和难度。ChemBench不仅涵盖选择题,还包括开放性问答,以更贴近化学教育和科研实际。
通过与19位具不同专长及经验的人类化学专家对比测试,结果显示部分最先进的语言模型在整体答题准确率上超过了人类专家平均水平,甚至某些模型超过了表现最优的人类参与者。 这一发现具有重要意义。它表明,经过充分的训练和优化,大型语言模型可以成为强有力的化学知识载体和问题解决工具。尤其是在处理大量文献和数据时,模型能够快速整合信息,辅助科学家生成新假设或设计实验,极大提升研究效率。对于教育领域,这样的技术或能促使教学重心转向培养学生的批判性思维与化学推理能力,而非仅依赖记忆知识点。 然而,ChemBench的详细分析也指出,模型表现因化学子领域的不同而差别显著。
例如,通用化学和技术化学领域,模型表现非常好;而在分析化学、安全和毒性评估等领域则相对薄弱。部分原因是这些领域知识更依赖专业数据库,模型训练中难以充分涵盖。此外,对于分子结构的深入推理能力有限,比如根据分子对称性判断核磁共振(NMR)信号数量,模型整体表现欠佳,反映出其在分子拓扑和空间结构推理上的不足。 同样重要的是,大型语言模型目前尚未能有效捕捉和复制化学家的“化学直觉”这一复杂的偏好判断能力。通过对比模型与人类专家在药物筛选早期化合物偏好的判断任务中表现,研究显示模型的选择往往与人类偏好难以一致,表现接近随机猜测。这表明目前的预训练和微调策略尚未深度嵌入人类专家的经验和判断逻辑,这一点在未来的模型优化中是关键的研究方向。
在安全和责任方面,语言模型的“过度自信”问题需要引起高度关注。在化学尤其是涉及危险化学品的场景中,错误指导可能直接引发严重后果。虽然部分模型能通过设定安全机制拒绝回答潜在危险问题,但不能完全避免误导性输出的风险。此外,模型对化学领域的知识更新较慢,部分内容可能滞后于最新科研进展,这也限制了其实时实用性。 因此,专家一致认为,为了更好地发挥大型语言模型在化学领域的潜力,需要构建更为完善的评估和监管框架。这包括像ChemBench这样专门针对化学领域开发的评测体系,帮助研究者全面把握模型能力,同时识别其盲区和潜在风险。
未来还需要结合专业数据库和实验数据,发展多模态模型,提升分子结构理解和推理能力,增强安全性和可靠性。 此外,人机协作将是化学发展的重要方向。相比单一依赖人工或单一模型,结合化学专家的经验与语言模型的高速数据处理能力,能够实现优势互补,促进科研创新和教育改革。通过设计友好的人机交互界面,化学家可以更加高效地获取信息、设计实验和验证假设,同时模型也能通过反馈机制逐步优化自身表现。 值得注意的是,大型语言模型的发展也带来伦理和社会挑战。其潜在的“二元使用”风险,比如设计有害化学物质的可能性,需要制定严格的使用规范和风险控制策略。
公众和学生在使用这些工具时,必须具备足够的化学基础和批判意识,避免盲目信赖模型输出造成危害。 总的来说,大型语言模型在化学知识和推理能力上展现出了令人瞩目的成就,部分顶尖模型甚至已经超越了一般人类化学专家的水平。它们能够辅助化学家处理庞大的文献和数据资源,促进新知识的发现和应用,推动化学教育方式向更注重理解与推理转变。然而,目前的模型仍旧存在记忆事实不全、结构推理不足、偏好预测失准以及自信度估计不可靠等限制。未来的研究应着眼于提升模型的专业知识覆盖、推理深度和安全性,同时强调人机协作与伦理规范的建设,以确保人工智能真正成为推动化学科学进步的有力引擎。