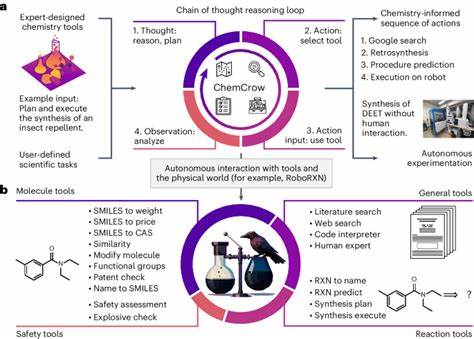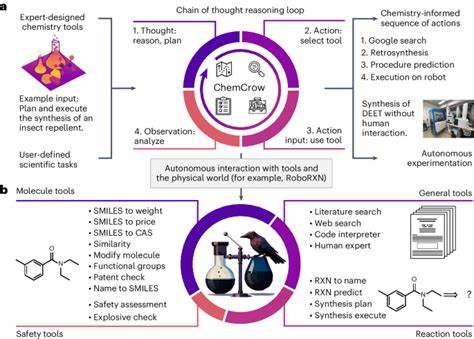
随着人工智能技术的快速发展,大型语言模型(LLM)在各个学科领域展现出了令人瞩目的潜力。尤其是在化学领域,这些模型能够处理大量文本信息,模拟人类语言的表达,甚至帮助科学家设计反应、预测分子性质和辅助实验。然而,尽管它们拥有海量数据支撑和强大的计算能力,LLM在化学知识掌握和复杂推理能力方面与专业化学家究竟存在怎样的差距?未来大型语言模型能否取代或辅助人类专家,推动化学科学的进步?本文将围绕这些核心问题进行深入探讨,结合最前沿的研究成果,揭示大型语言模型与化学专家在知识与推理表现上的差异,分析其瓶颈和提升空间,并探讨其对化学教育及科学研究的深远影响。 大型语言模型的发展历程及其化学应用 大型语言模型是一类基于深度学习技术的自然语言处理工具,通过海量语料库的训练,能够理解、生成甚至推断自然语言文本内容。近年来,随着模型规模和训练数据量的激增,LLM在医疗、金融、法律等多个专业领域已展现出较强的推理和知识运用能力。化学科学作为一个高度专业化的领域,长期以来积累了大量文本式的知识,包括科研论文、专利文献、教材和数据库等,这为LLM提供了丰富的训练素材。
在化学中,LLM能够胜任诸如化学结构公式描述、反应机理解析、分子性质预测等任务。通过对文本信息的挖掘,它们能够辅助化学家快速获取文献资料,提取关键信息,甚至设计全新的化学反应和材料合成路线。如部分基于LLM的系统已经实现了实验操作的自动化指令生成,成为化学家得力的“语言助理”。 基于这些技术进展,科学界提出了诸多关于LLM在化学领域能力的评估框架,化学知识和推理能力的系统化测试日益成为研究热点。 ChemBench评分体系:对比大型语言模型与专家水平 为了系统衡量大型语言模型在化学领域的表现,科学家们开发了名为ChemBench的评测框架。该框架涵盖了涵盖本科及研究生化学课程的2700多个题目,囊括从基础知识掌握到复杂推理、多步计算及化学直觉等多层面能力的任务。
通过精心设计的问答对,ChemBench能够客观反映模型对化学知识的理解深度以及推理准确率。 有趣的是,部分顶尖的LLM模型在整体测评中,表现甚至超过了部分专业化学家。尤其在课本问题和机械记忆层面的知识问答,模型表现相当出色,但在涉及复杂分子结构推理或创新性判断的题目中,模型普遍遇到瓶颈。更令人担忧的是,模型往往对自己的回答过于自信,缺乏对错误风险的合理估计。 通过与人类专家的对比测试,还发现模型在不同的化学子领域存在显著性能差异。一般基础化学和技术化学问题模型表现较佳,但在毒性、化学安全及分析化学等领域则相对薄弱。
这反映出模型训练语料和知识库的局限,以及其在推理与直觉判断层面的不足。 LLM在化学推理方面的限制及其背后原因 虽然大型语言模型在储存与复述化学知识方面表现优异,但推理能力本质上受限于其训练机制。LLM通过概率预测下一个词的方式生成文本,缺乏明确的符号逻辑推演架构。这导致它们在处理需要空间想象、分子立体对称性分析或复杂分步实验设计时,表现不尽如人意。 此外,模型在分子结构表示上也存在障碍。目前许多模型只接触到如SMILES等线性化的分子字符串,这种表示无法完全反映三维分子拓扑和动态构象,使复杂谱图信号预测等任务难以准确完成。
相比之下,化学专家在多年训练中积累了直觉和经验,能够结合结构、光谱及实验信息进行推断,优势明显。 另一个重要因素是数据源的局限性。模型所依赖的文本训练数据多为公开文献,但很多关键的专有数据库或者实验数据并未全面纳入训练集。此外,某些化学安全及毒性信息涉及敏感内容,模型因内置的安全机制或政策限制,有时无法输出相关信息,进一步影响了应用的广度。 从计量角度看,模型性能与其规模呈现正相关。更大规模、更多特定领域数据训练的模型通常具备更强的记忆及部分推理能力,但简单堆叠模型参数并不能彻底解决推理本质的问题。
未来需要结合符号推理、知识库检索及多模态数据处理等技术,提升模型的化学推理深度。 模型自信度与风险评估的困境 在科学研究与实际应用中,模型对输出结果的置信度评估极为关键。令人遗憾的是,多数大型语言模型当前尚不能准确判断自身回答的可靠性。研究显示,模型在提供错误答案时反而往往伴随着较高的“自信”打分,这种误导性极大增加了模型在化学安全或实验设计等关键领域的风险。 这一现象的根源在于模型本身的概率语言生成机制,并未内置真正的误差校验和风险反馈环路。虽然通过设计特定的提示语、合并外部知识库或引入模型融合可能部分缓解,但整体上仍需未来研究突破。
科学家呼吁在开发化学领域应用时,务必引入多层次的验证机制,由人类专家监控和校正,防止错误传播和潜在危害。 从教育视角看,LLM对化学学习的影响 大型语言模型的崛起正在推动化学教育范式的变革。传统依赖机械记忆和重复练习的教学模式,正面临挑战。因为LLM能够快速提供标准答案和详细解释,学生可能不再需要费力记忆大量化学事实,而应更多注重理解复杂概念、培养批判性思维和实际操作能力。 研究显示,模型在标准教科书问题上的高准确率,提醒教育者必须重新思考考试设计和知识考核方式。未来化学教育或将更多引入开放式问题、创新设计和实验推理,突出科学探究精神和实践经验,促进学生深度学习而非死记硬背。
同时,LLM对辅助学习工具的扩展也具有巨大潜力。基于语言模型的交互平台可以即时解答学生疑问,提供多样化的学习资源,个性化推送内容,真正成为学生与教师的有效补充。然而,也必须警惕过度依赖人工智能带来的浅层学习风险,强调科学诚信和独立思考的重要性。 未来展望:融合人机合作促进化学创新 尽管当前大型语言模型在化学知识和推理上展现出非凡潜力,但距离真正模拟或超越人类专家的科学推理能力尚有差距。未来的发展方向应侧重于加强人机协作,发挥模型的海量信息处理优势,搭配专家的批判性分析和创造性思维。 多模态模型的研发将成为关键。
结合文本、结构式、光谱图和实验数据的统一处理,赋予模型更强的空间和实验理解能力。此外,结合知识图谱和符号推理机制,可提升模型在复杂任务中的逻辑推断水平。融合数据库检索和安全防护机制,将保障模型输出的科学性和合规性。 最终,化学领域的人工智能工具将不再是单纯的答案生成机,而将演化为真正的“数字助理”和“科学伙伴”,帮助研究者扫清文献信息壁垒、优化实验设计流程、加速新材料和药物发现。与此同时,化学教育也将迎来新的时代,更加关注模型辅助下的人类创造力培养和科学素养提升。 总结来说,大型语言模型已经在化学知识掌握上展现出超越部分专业人员的实力,尤其是在事实记忆和语言表达方面。
然而,它们在复杂化学推理、直觉判断以及置信度校准等核心领域仍显不足。通过系统评测框架ChemBench的验证,我们看到了人工智能与人类专家各自的优势和不足,也明确了未来融合发展的路径。化学科学正迈向一个人机协同创新、智能加持科研的新纪元,需要我们及时调整教育理念,完善工具安全性,激发科技创新活力,迎接智能化时代的挑战和机遇。