SCHEME-78是将Lisp(尤其是Scheme方言)的核心观念直接映射到硬件上的一次早期探索。它由Guy Steele和Gerald Sussman在20世纪70年代末至80年代初推动,在MIT人工智能实验室的背景下提出,目标是设计一种"以Lisp为指令集"的处理器。与传统的冯·诺依曼机器不同,SCHEME-78把程序和数据视为统一的、链式记录结构,从体系结构层面支持符号表达式、闭包和动态分配,从而为高级语言特性提供直接的硬件支持。 在设计动机上,SCHEME-78基于Scheme语言的两个重要特性:程序作为数据的可操控性和基于链表/树的内部表示。传统处理器操作的是定长指令和索引内存向量,而Lisp主要使用异构的、可变长的记录(cons单元、符号、结构体等),这些记录更像是一个无序的链式图而不是线性的地址空间。SCHEME-78的核心思想是把这些链式记录结构的操作作为一组原生硬件指令,从而消除大量在软件层面解释S表达式时的开销。
通过在指令集中引入对car、cdr、cons、eq等基本原语的直接支持,以及对环境和闭包的硬件友好表示,解释器可以更高效地执行Scheme程序。 在实现细节方面,SCHEME-78引入了带标签的指针格式。每个字或指针都会带有类型标签,区分原子、指针、整数、代码指针等。标签机制使得在硬件中快速识别数据类型成为可能,从而在执行函数调用和垃圾回收时简化判断逻辑。为表达树形结构,内存被组织为一组记录(record),每个记录包含若干字段,字段可以引用其他记录。硬件提供对这些记录进行分配、读写和链接的原语,而不是仅仅依赖于软件库来管理内存布局。
存储管理与垃圾回收是SCHEME-78设计中最具挑战的部分之一。Lisp程序大量依赖短命对象和频繁分配,若无高效管理会导致性能灾难。设计中考虑了在硬件中实现或协助实现自动存储分配与回收的方案,例如快速分配器(bump-pointer allocator)、基于空闲链的分配器以及对复制式垃圾回收(如Cheney算法)的硬件加速。实现的微型原型包含了一个简易的存储分配器,用以演示在芯片级别实现动态分配的可行性。同时也探索了增量式和并发垃圾回收的思路,以减少GC停顿对互动式开发环境的影响。通过在硬件中支持一些GC友好的操作(如原子对象的移动、指针重写等),垃圾收集器可以更高效地进行堆压缩或复制。
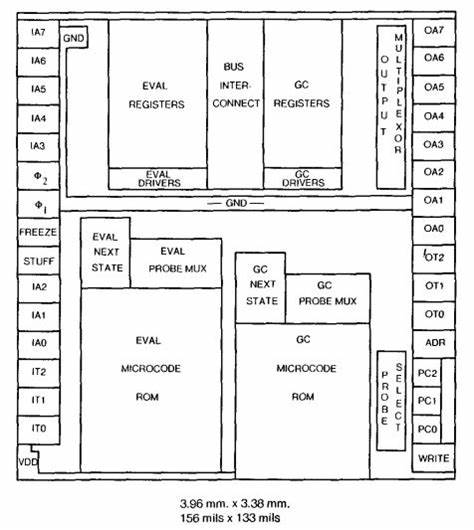
指令集设计方面,SCHEME-78并非简单地把传统汇编指令替换为Lisp原语,而是设计了一套递归解释器风格的执行机制。处理器能够以递归方式遍历程序表示的树结构,并对每个节点应用相应的处理规则。与基于堆栈的调用模型不同,这种设计更自然地匹配函数式语言的求值策略,例如应用(apply)、延迟(delay)和first-class continuations。为支持高阶函数与闭包,处理器提供了对环境帧的直接表示与操作指令,使得捕获自由变量与函数实例化的开销最小化。此外,为了实现优化如尾递归消除,硬件执行路径对尾调用给予特殊处理,避免不必要的栈增长。 在VLSI实现与微处理器原型方面,SCHEME-78团队在当时的技术条件下制作了小规模芯片原型,演示了基本指令解释器和初步的存储分配功能。
受限于1980年代的工艺,芯片规模与速度不能与通用CPU相提并论,但原型成功验证了若干关键假设:把数据结构原语实现为硬件指令可以显著简化解释器的实现,使得一些Lisp操作在通量上有实质提升;硬件辅助的分配器和GC原语能够降低存储管理的总体开销。该设计也延续并影响了同时代的Lisp机器研究,例如MIT的Lisp Machine项目和早期的CONS微处理器实验。 SCHEME-78的设计在理论与工程之间取得了有趣的折中。理论上,支持高阶函数、动态类型和程序即数据的计算模型在硬件层面能带来整洁的映射;工程上,将复杂的语言语义塞入受限的硅片会面临面积、功耗与复杂性三重约束。因此设计者不得不在指令集的完整性与芯片复杂度之间做出选择,通常通过提取最常用的原语并将其硬件化,而把复杂且少见的特性保留给软件处理。这样的分层策略为后来很多高级语言的运行时优化提供了启发。
从历史影响看,SCHEME-78推动了对语言驱动架构的兴趣,尤其是在人工智能和符号计算的语境下。尽管大多数商业处理器选择了通用指令集并依赖高效的编译器或JIT,但SCHEME-78展示了垂直定制(language-specific hardware)在特定场景下的潜在优势。Lisp机器和后来的研究中很多思想可以追溯到这一系列工作,例如对内存表示、垃圾回收友好型指令的关注、以及对解释器结构的硬件协助。时至今日,随着FPGA和片上系统技术的发展,重新思考语言专用加速器变得更为现实,SCHEME-78的经验仍然有参考价值。 在现代语境下,SCHEME-78提出的问题和解决方案与当前的研究热点高度相关。函数式语言的执行效率、快速内存分配、低延迟的垃圾回收、以及对高阶抽象的硬件支持都是云原生服务、函数即服务(FaaS)和高性能计算关注的主题。
利用硬件来加速对象分配和指针跟踪、将元编程或某些运行时服务下移到硬件层,都能够降低软件复杂度并提高吞吐率。另一方面,SCHEME-78也提醒我们,语言与硬件的紧耦合会降低平台通用性,因此在实际工程中更现实的路线是软硬结合:在可重构硬件(如FPGA)上实现关键原语,配合灵活的软件运行时来处理边缘场景。 此外,SCHEME-78在可维护性与可扩展性方面的设计思路也值得借鉴。将语言解释器模块化并在硬件中实现稳定、高频次的核心操作,可以使上层优化与编译技术更专注于语义优化而非基础设施。当代编译器和运行时系统可以把SCHEME-78的硬件原语视为一种"加速器接口",在JIT编译阶段生成调用这些原语的代码路径,从而获得近硬件级别的性能提升。 总结而言,SCHEME-78不仅是一次技术实验,更是对计算机体系结构和编程语言关系的深刻反思。
它表明语言的抽象并不一定只能在软件层面实现,硬件设计可以直接反映高级语言的语义,从而带来性能和开发体验的双重收益。虽然时代与工艺限制使得完全由Lisp驱动的处理器未能成为主流,但其中关于数据表示、内存管理、硬件辅助垃圾回收与原语级加速的洞见,对今天重新审视领域专用硬件、运行时协同优化与功能性语言加速仍具有重要的参考价值。对于希望在现代平台上实现函数式语言高效执行的工程师与研究者而言,SCHEME-78提供了丰富的设计范式与实践教训,值得在FPGA原型、芯片级加速器与运行时协同优化中继续挖掘与发展。 。