许多人在处理扫描件或手机拍照生成的PDF时会遇到文字模糊、打印效果差的问题。模糊文字不仅影响阅读体验,还会妨碍后续的文字识别和编辑。要想把存储在PDF里的模糊文本变得清晰,需要理解PDF中文本的两种形式,以及不同场景下的最佳处理策略。掌握正确的流程和工具,既可以提高单页质量,也能实现批量处理与自动化,满足办公与档案保存的需求。 首先需要判断PDF中"文字"的实际类型。PDF文件可能包含可选文本层,即真正的字符信息,这样的文件可以直接选择和复制文字;另一种情况是PDF只是将整页扫描为一张或多张图像,文字实则以位图形式存在。
若是位图格式的文字,就需要通过图像处理或光学字符识别(OCR)来改善可读性。判断方法非常直接:尝试用鼠标拖选页面文字或在PDF阅读器中搜索关键字。如果不能选中或搜索无效,则该页很可能是图像。 对图像化文字进行锐化的第一步是提取图像资源。许多PDF编辑器如Adobe Acrobat Pro可以导出嵌入的图片,也可使用开源工具如pdfimages(来自Poppler套件)一次性提取每页的位图。导出后,先不要急于放大或锐化,而是查看原始图像的分辨率和颜色模式。
扫描或拍摄的图像通常分辨率偏低(例如100到200 DPI),而打印或阅读理想分辨率通常至少为300 DPI。若图像本身像素不足,单纯锐化只能在有限程度上提升视觉清晰度,此时需要考虑超分辨率重建或重新OCR并替换文字。 图像预处理包含去噪、色彩与对比调整、二值化和锐化等步骤。去噪可以去除扫描过程中产生的斑点和纸张纹理,常见工具有Photoshop滤镜、GIMP的降噪插件或ImageMagick的去噪参数。调整色彩和对比可以增强字符与背景的差异,使用曲线或色阶将文字层拉得更深更纯,背景变得更纯净。对于黑白文本,合适的二值化策略非常关键。
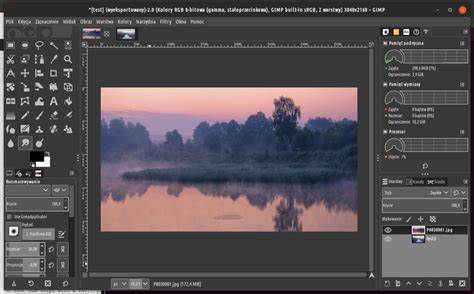
简单的阈值二值化可能导致断字或细线消失,而自适应阈值或局部二值化算法更适用于光照不均的扫描件。完成上述处理后再进行锐化,往往能获得更好的结果。 锐化方法多样。传统图像编辑软件常用的有Unsharp Mask(反锐化掩模)和High Pass(高通滤波)混合法。反锐化掩模通过增强边缘对比来提升文字的清晰感,参数需要根据源图像试验调整,半径过大会产生晕影,强度过高会导致锯齿感。高通滤波配合图层混合模式可在不破坏整体细节的情况下强化边缘。
对于批量处理,可以使用ImageMagick命令行工具或Photoshop的动作功能批量应用预设参数。 近年来AI超分辨率技术为低分辨率OCR和模糊文本的再生提供了崭新的途径。开源项目如Real-ESRGAN和ESRGAN可以将低像素图像放大并重建细节,商业软件如Topaz Gigapixel AI也能显著提升文字边缘的锐利度。使用超分辨率时建议先进行去噪和对比优化,然后对图像应用超分辨率模型,最后再做细微的锐化和去锯齿处理。需要注意的是,AI重建并非完美无缺,某些模型可能在人为重构细节时引入伪影或不规则笔画,尤其是在复杂字体或手写体上。因此在进行批量处理前应对样例页进行测试。
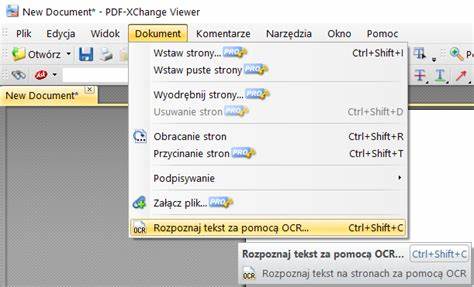
OCR在处理PDF文字时扮演重要角色。若目标是将模糊的扫描页转换为可编辑、可搜索的文本,强大的OCR引擎是关键。ABBYY FineReader以其高准确率著称,能在保留版式和颜色的同时输出可编辑文档。Tesseract是开源且可扩展的OCR引擎,配合图像预处理能取得不错效果。OCR流程中尽可能提供高质量的图像输入:提高DPI、去除噪点、增强对比、使文字成为最突出元素,都会帮助识别率显著提升。识别后如果生成了文本层,可以在PDF编辑器中将识别出的文字与原位图叠合或直接替换,从而在打印时得到矢量文字的清晰输出。
如果目标是保留原始版式但替换模糊文字为新的字体,有两条主流路线。第一条是将OCR识别出的文字导出为可编辑文档(如Word或InDesign),在保留布局的前提下调整字体、间距和段落,然后重新导出为PDF。第二条是手动在PDF编辑器或排版软件中遮盖原文本区域并插入新文字。第一条适合大量文本且需要可编辑档案的场景,第二条适合少量页或需严格保留版面细节的情况。无论哪种方法,选择相近风格的字体并微调字距和行距可以最大程度还原原始版式。 处理包含复杂排版、表格或多列布局的扫描件时,需要格外小心。
OCR在表格边界识别和列流程上容易出错,导出为Word后常常需要手动校正。针对这种情况,专业OCR软件提供保留布局的导出选项,可以把版面结构尽量保留,但仍需校对。对于重要文档,人工校正是不可或缺的一步,即便是最先进的OCR也难以在所有情况下做到百分百准确。 打印优化是最后一环,许多用户在屏幕上觉得可读但打印出来却不理想。打印效果受图像分辨率、PDF嵌入图像质量、打印机驱动和纸张质量的影响。要获得清晰打印,建议将处理后的图像调整到至少300 DPI,最好是600 DPI以获得极致细节。
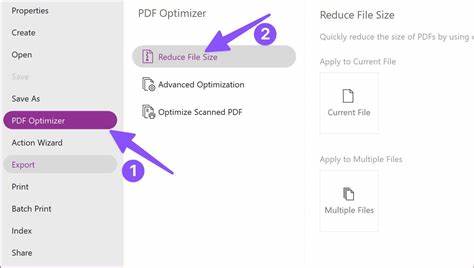
导出PDF时选择嵌入高质量图像而非压缩过度,避免使用高压缩的JPEG参数。打印前做样张测试,调整打印机的锐化与色彩配置,必要时选择专业打印服务以确保纸张与墨水匹配文档需求。 在隐私与安全方面,处理敏感文件时需格外谨慎。不要将机密扫描件上传到不受信任的在线服务,若使用在线OCR或AI工具,务必阅读隐私政策并选择支持本地处理或明确删除上传内容的服务。对于企业级需求,考虑在内部服务器上部署OCR或超分辨率解决方案,避免外部数据泄露风险。 实际工作流程推荐从简单到复杂依次尝试。
先判断PDF类型,若含有文本层优先提取并使用矢量文本替换。若为图像,先提取图片并做去噪与对比调整,再根据分辨率选择直接锐化或先做超分辨率重建。随后运行OCR获取文本层并进行校对,最后将处理后的图像或文本重新合成PDF并导出高质量打印版本。对大量文档,可把处理步骤脚本化或使用批处理工具来提高效率。 工具推荐方面,Adobe Acrobat Pro适合提取图像、进行OCR和替换文本层的工作;ABBYY FineReader在文字识别和版式保留上表现优异;Photoshop和GIMP适合精细的图像修复与锐化;ImageMagick和Ghostscript适合自动化批量处理;Real-ESRGAN与Topaz系列适合超分辨率重建。移动端用户可以尝试Microsoft Office Lens或CamScanner进行初步拍照优化,但对于最终打印质量的提升仍建议在桌面端完成更精细的处理。
总之,要把PDF里模糊的扫描文字变清晰,需要从判断文件类型入手,结合图像预处理、合适的锐化策略、必要时的AI超分辨率重建以及高质量的OCR。不同工具各有优势,应根据文档类型、工作量和隐私要求选择最合适的组合。通过科学的流程和反复测试,模糊文字往往可以得到显著改善,从而满足阅读、编辑和打印的需求。保存好原始文件并在每一步保留中间版本,可以在出现问题时回滚或尝试不同参数,最终达到既清晰又保真度高的PDF效果。 。