当你打开一个 PDF 文件并尝试使用"查找"或"搜索"功能却得不到任何结果时,那种挫败感很常见。表面上看文件可以被打开,文字似乎存在,但搜索却毫无反应。要解决这个问题,需要逐步排查可能的原因并运用合适的工具。本文将从用户最常遇到的情形入手,解释背后的技术原因,并给出可操作的修复与替代方案,适用于 Windows、macOS 和 Linux 平台。 首先明确一个基本判断方法:尝试用鼠标选中可见的文字。如果无法像普通文本那样选中并复制,说明页面上的"文字"实际上是图片或扫描件,此时本质问题是缺乏可搜索的文字层。
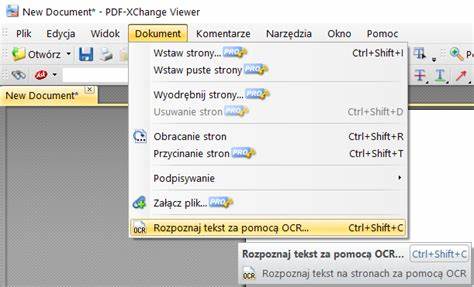
相反,如果可以选中并复制出可读文本,却仍然无法通过搜索功能定位,问题通常出在编码、字体嵌入或文档索引等技术细节上。 不可选中文本且为图片层时的解决路径是 OCR(光学字符识别)。OCR 可以把图像上的文字识别为真实的文本层,从而恢复搜索和复制功能。常见的商用 OCR 工具有 ABBYY FineReader,开源工具有 Tesseract。使用 ABBYY 时可以直接导入 PDF,选择"将扫描文档转换为可搜索 PDF"或"可编辑文档",经过识别后保存为新的 PDF。使用 Tesseract 的命令行流程通常是先把 PDF 转为图像序列,例如使用 Ghostscript 或 ImageMagick,然后对每页运行 tesseract page.tif page -l chi_sim pdf 来生成可搜索的 PDF。
对于大量文档,建议使用批处理脚本或专业软件集中处理。 如果可以选中文本却搜索无效,常见原因包括字体被子集化且编码混乱、文字被转换为特殊字形导致映射不正确、或文档中包含不可见的控制字符和非标准 Unicode 编码。在这种情况下,复制一段文字到记事本或文本编辑器,查看复制结果是否与页面上显示一致。若复制后字符变成乱码或字形错乱,说明字体编码或映射存在问题。解决方法可以尝试用 PDF 编辑或打印到虚拟 PDF 的方式重建文本层。把页面内容导出为纯文本(例如使用 pdftotext 工具),如果导出的文本乱码,则需考虑重新生成 PDF 源文件,或用 Adobe Acrobat Pro 的"识别文本"功能重新 OCR 一次以恢复标准编码。
另一种不常见但真实存在的情况是文档经过了特殊保护或使用了"内容提取"限制。尽管文档属性中显示没有严格的安全限制,有时作者会采取内嵌脚本、限制可搜索索引的设置或以特定方式生成 PDF,导致标准阅读器无法正确索引文本。用不同的阅读器测试通常能帮助判断。例如用 SumatraPDF、Foxit Reader、Okular 或浏览器自带的 PDF 查看器打开并尝试搜索,如果某些阅读器可以搜索而其他不行,问题可能在阅读器对特定 PDF 版本或特性的支持差异。此时更新阅读器或切换到兼容性更强的工具通常能解决问题。 搜索功能失灵有时与阅读器本身的插件或加速功能相关。
曾有用户反映 Adobe Reader 的加速或某些插件会影响搜索行为。遇到这种情况可以尝试在 Adobe Reader 中禁用"加速"或卸载可疑插件,再重启程序重试。若怀疑软件故障,升级到最新版或回退到稳定版本也能验证原因。 如果问题发生在大量文档的全文搜索(例如桌面搜索或企业级索引)而非单个文件,需检查操作系统的索引服务。Windows 的索引选项和 macOS 的 Spotlight 都依赖于 PDF 的文本层和合适的索引器插件。确保系统索引器支持所用 PDF 类型和语言,必要时重新编制索引或添加适当的 PDF iFilter。
对于中文 PDF,Windows 上的 iFilter 和编码支持尤为关键,建议安装支持中文的 iFilter 或在服务器端使用第三方搜索引擎配合专业解析器。 在某些情况下,PDF 的版本和生成方式会影响搜索。某些从页面排版软件导出的 PDF,采用了自定义编码或把文本作为路径(outlines)保存,以确保打印和显示一致,但牺牲了文本的可选和可搜索性。检查文档属性和 PDF/A 兼容性也能提供线索。若源文件可访问,建议在导出 PDF 时选中"保持可搜索文本"、"嵌入字体"并避免把文本转曲,这样既保证视觉效果也保留文本层。 当你需要快速定位文本但无法直接修复 PDF 时,可以考虑将 PDF 转换为其他可搜索格式作为权宜之计。
把 PDF 转为纯文本或 Word 文档既能恢复搜索,也方便编辑。常用工具包括 Adobe Acrobat Pro 的导出功能、在线转换服务以及开源工具 pdftotext 或 pdf2docx。注意选择靠谱的工具以避免泄露敏感信息,若文档涉及机密,尽量在本地环境使用受信任软件完成转换。 对技术用户而言,使用命令行工具能更灵活地诊断问题。运行 pdffonts 命令可以显示 PDF 中使用的字体及其嵌入状态。若发现字体未嵌入或字体名为"Unknown"或以 CID 编码出现,说明字体映射存在潜在问题。
使用 qpdf 或 Ghostscript 可以尝试重新生成 PDF,命令类似于 gs -sDEVICE=pdfwrite -dCompatibilityLevel=1.4 -dPDFSETTINGS=/prepress -o output.pdf input.pdf,通过这种方式重写 PDF 有时能修正内部结构错误并恢复搜索功能。不过这类方法并非万无一失,对复杂的字体编码问题可能无效,仍需结合 OCR 或重新导出源文件的手段。 在线 OCR 服务是方便但需谨慎的选择。若文档不含敏感数据,可以上传到可靠的 OCR 网站进行识别并下载可搜索 PDF。免费服务通常有限制,商用服务或桌面软件在识别率和隐私保护方面更有保障。对于中文识别,确保选用支持简体或繁体中文的 OCR 引擎,并在识别前预处理图片以提高清晰度,例如裁剪边缘、去噪和提升对比度。
企业级场景中,建议建立标准化的 PDF 生成与存档流程。规定导出选项确保文本层完整、嵌入字体并使用广泛兼容的 PDF 版本,同时为扫描件统一执行 OCR,并把 OCR 后的可搜索 PDF 保存为主版本。对历史文档进行批量 OCR 与重建索引可以显著提升检索效率和可用性。 最后给出一些常见的排查顺序便于快速定位问题。先判断文本是否可选中并复制;如果不可选中,直接进入 OCR 流程;如果可选中但复制出乱码,检查字体与编码并尝试重写 PDF 或重新识别文本;如果只有特定阅读器无法搜索,尝试更换或更新阅读器;如果问题在系统索引层面,检查索引服务和语言插件。对于每一步,记录操作和结果可以帮助缩小范围,必要时将问题示例提供给技术支持或论坛以获得更针对性的帮助。
总结建议包括保持 PDF 源文件的良好导出设置,使用 OCR 恢复扫描件的文本层,定期更新阅读器与系统索引插件,以及在处理敏感文件时优先选择本地工具或受信任的企业解决方案。面对搜索功能失灵的问题,耐心排查并结合合适的工具,通常都能找出根本原因并恢复全文检索能力。通过建立规范化流程与备份策略,可以在未来最大限度避免重复发生类似困扰。 。