在处理纸质书籍的数字化存档时,常见的一种扫描方式是每张JPG包含两页书籍内容。虽然这种方式在扫描速度和纸张保护上有优势,但要把这些双页图像转换为章节清晰、页序正确的PDF电子书,通常需要进行切割、校正、排序与合并等多个步骤。本文面向希望把扫描图批量转为电子书的个人和小型团队,提供可实际操作的流程、开源与商业工具建议,以及提高输出质量的技术细节与注意事项。 首先明确目标和输出格式。你可能需要两类PDF:一种是"图像型PDF"(每页以图片形式存在,不进行文字识别),适合保留原始图像、复杂排版或含有大量截图的书籍;另一种是"带文字层的可搜索PDF"(结合OCR识别),便于检索与复制文本,但对含图片文字或版式复杂的页面可能引入识别错误。决定好目标后,才能选择合适的工具和参数。
准备工作包括确定页面排列方式和扫描质量。建议扫描分辨率设为300 DPI或更高,书籍含小字体或细节时考虑400-600 DPI。选择灰度或彩色取决于原书是否含大量彩色图片或需要还原色彩。扫描时注意页面平整、光源均匀、避免阴影和窄边距。若扫描仪支持自动对齐与去斑点功能,先在扫描阶段尽量优化原始图像,后续处理会更省力。 切割双页图像为单页是核心步骤。
常见方法有图形界面工具和命令行工具。图形工具例如ScanTailor、Briss或PDFsam的裁剪功能适合试验和手动微调;命令行工具如ImageMagick(Windows、macOS、Linux通用)便于批处理。ImageMagick切割的示例命令为:magick input.jpg -crop 50%x100% +repage out_%d.jpg。这会把横向并排的两页平均分为左右两张图片。需要注意左右页可能包含不同边距,若书脊处被摄成阴影或有失真,先用deskew和去光晕工具处理,再裁切更可靠。 批量处理时要解决页序问题。
扫描设备通常以每张图像包含左页和右页的顺序输出,切割后应按照阅读顺序重新编号。一个常见做法是对每张原始图片生成两个文件,命名为例如0001_L.jpg和0001_R.jpg,然后把它们按序交替重命名为0001.jpg、0002.jpg等,以确保合并为PDF时页顺正确。用脚本自动化命名和重排序会节省大量时间,常用脚本语言包括Python(Pillow库或调用ImageMagick)、Bash结合imagemagick与rename命令。 裁剪边距与纠正倾斜也是必要步骤。ScanTailor是专为扫描后处理设计的开源工具,能够自动检测内容边界、裁剪和纠偏,并提供手动微调界面。对于大量图片,先在一个样本上设定参数,再应用到整批图像可以提高一致性。
如果偏差不一,建议分组处理。无论使用何种工具,注意保留书脊附近的文字完整性,避免过度裁切导致字被截断。 图像优化会直接影响最终PDF的清晰度与文件大小。常见操作包括去噪、锐化、对比度调整和颜色模式转换。对黑白文字书籍可以考虑二值化,但要谨慎:过度二值化会导致小字断裂或图片失真。对于含大量截图或照片的书籍,采用JPEG有利于减小体积,但注意压缩率不要过高以免出现明显压缩伪影。
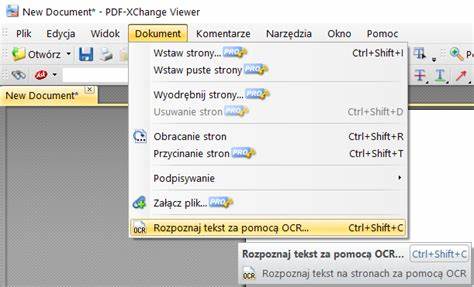
选择无损的PNG或将图片直接以原始JPG嵌入PDF在保证质量的同时并不总是最优,因为PDF合并工具有时会再次压缩图片。img2pdf是一个将图片原封不动嵌入PDF的工具,适合保留原始质量:img2pdf *.jpg -o output.pdf。 如果需要可搜索的PDF,OCR步骤不可缺少。ABBYY FineReader在精度和版式还原上表现优异,支持批量处理和输出带文字层的PDF,但商业授权费用较高且对图片中图片(如截图内文本)识别效果有限,可能导致版面错位或图片被解析成文本。开源替代是Tesseract,配合合适的预处理(去噪、二值化、倾斜矫正)能显著提升识别率。一个典型流程是先使用ImageMagick或ScanTailor处理图像,再用tesseract input.jpg output pdf创建带文字层的PDF。
对于中英文混排文档,需配置相应语言包并进行字符集校验。 合并与整理PDF时要考虑书签、章节和元数据。Calibre和Adobe Acrobat Pro能方便地添加元数据、封面和书签,便于阅读器导航。若倾向于开源工具,pdfunite(Poppler)或Ghostscript可以完成简单合并:gs -dBATCH -dNOPAUSE -q -sDEVICE=pdfwrite -sOutputFile=output.pdf input1.pdf input2.pdf。合并后检查页面方向、偶数页与奇数页的排版,必要时插入空白页以保持章节前置在右页。 处理扫描异常情况的技巧也很重要。
若扫描中出现奇数页导致最后一页单独为单页图像,应在合并前插入一张空白页或封底图片以维持阅读器的两页显示一致。若页面顺序错乱,可利用PDFtk、pdfarranger或Python脚本重新排序。遇到每张图像左右页不对称,需要在裁切时为左右页分别设置不同的裁剪框,这时可使用带模板功能的工具或编写脚本计算每张图片的具体裁剪坐标。 在移动平台与快速场景下,也有便捷方案。手机App如Adobe Scan、CamScanner等支持自动裁切与保存为PDF,但通常以单页为主,对双页JPG的批量切割支持有限。若扫描时就调整为单页会更简单,但对于已有的大量双页文件,还是推荐在电脑上使用批处理工具完成切割与优化。
最后讨论文件压缩与兼容性。生成的PDF若用于发布或分发,考虑各种阅读器和存储限制,通常需要在可接受质量的前提下压缩文件。Ghostscript提供了多种预设(screen、ebook、printer、prepress)用于不同的压缩级别。另一个方法是在合并前对图片进行适度压缩或分辨率调整,从而在不显著影响阅读体验的情况下减少体积。若档案保存优先于文件大小,建议保留原始高分辨率文件并生成单独的压缩版供分发。 推荐的实用工作流可以分为三类:快速无OCR方案、质量优先带OCR方案和自动化批处理方案。
快速方案适合希望尽快生成可阅读PDF的用户,使用ImageMagick快速切割并用img2pdf合并即可;质量优先方案则会在切割前后进行ScanTailor处理以修正版面,再用ABBYY或Tesseract做OCR并在Adobe Acrobat或Calibre中添加元数据与书签;自动化批处理方案适合大量页数或多本书,结合脚本完成裁切、去噪、重命名、OCR与合并,必要时按不同组别分配不同处理参数。 无论采用哪种方法,保持备份尤为重要。尽量保留原始JPG备份,任何处理步骤出现错误都可以回退。处理完成后在多个阅读器上测试PDF的显示效果,尤其要检查左右页顺序、图片清晰度、OCR文本层与页面对齐情况。通过合理选择工具与参数,结合自动化脚本,可以高效地把双页JPG扫描图转换为质量可控、结构清晰的PDF电子书,既保留原始视觉效果,又满足阅读和检索需求。祝你在书籍数字化的过程中取得理想成效,如需针对操作系统或具体工具的脚本示例,可以提供更具体的实例与代码帮助你快速上手。
。