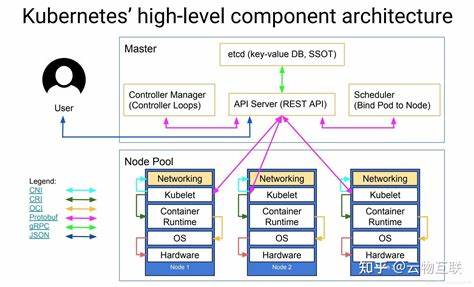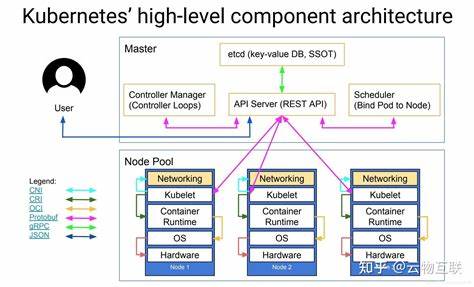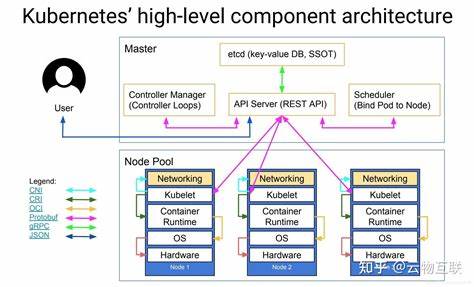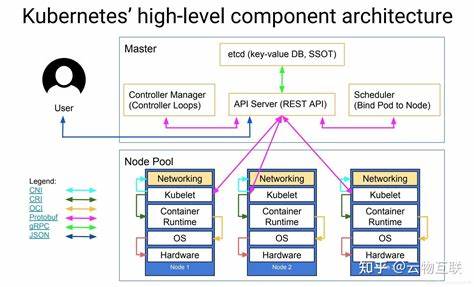
Kubernetes作为当下最流行的容器编排平台,已经从一个开源项目成长为云原生基础设施的代名词。很多团队在引入Kubernetes时会问一个根本的问题:它到底能做什么,为什么要使用它,以及在企业真实场景中能为我们带来怎样的价值。要回答这些问题,需要从技术能力、常见应用场景、运维成本与限制几个维度来全面剖析。 首先,Kubernetes的核心能力是容器编排与管理。它把散落在很多主机上的容器抽象为一组可声明的资源对象,通过声明式的配置来管理应用的生命周期。开发者可以只关注应用本身的镜像与配置,运维则通过Kubernetes把资源调度、网络、存储、配额与安全策略统一管理。
基于Pod的概念,Kubernetes实现了容器的分组、调度与副本管理,保证服务在节点故障或容器崩溃时能够自动恢复,从而实现高可用性。 自动伸缩是Kubernetes为云原生应用带来的重要能力之一。无论是基于CPU和内存的水平自动伸缩(Horizontal Pod Autoscaler)还是基于集群资源的集群自动伸缩,Kubernetes都能根据真实的负载动态调整实例数量和节点规模。这为应对突发流量、节省资源与优化成本提供了技术基础。结合自定义指标或外部指标,自动伸缩可以非常细粒度地适配不同类型的业务需求。 滚动更新与回滚机制让持续部署在生产环境中变得更安全。
Kubernetes原生支持无缝的滚动升级,能逐步替换旧版本实例并监控健康状态,如果新版本出现异常则可以快速回滚到稳定版本。这样的机制减少了部署时的风险,提高部署频次,配合CI/CD流水线可实现真正的持续交付。 服务发现与负载均衡是微服务架构的基础。Kubernetes通过Service对象实现内部DNS解析与集群内负载均衡,同时可以结合Ingress或云厂商的负载均衡器实现外部流量入口管理。配合服务网格技术(如Istio、Linkerd),可以在不改造应用代码的前提下实现流量管理、熔断、限流与链路追踪等高级能力,显著提升微服务的可观测性与弹性。 在状态ful应用的支持上,Kubernetes通过PersistentVolume和PersistentVolumeClaim抽象了存储资源,支持多种存储后端,使得数据库、消息队列等有状态服务也可以在Kubernetes上运行。
虽然有状态服务的运维复杂度高于无状态服务,但通过Operator模式可以把复杂的运维逻辑编码为控制器,实现自定义资源的自动化管理,从而简化数据库的部署、备份与恢复等操作。 安全与配置管理同样是Kubernetes的强项之一。通过Namespace、RBAC、NetworkPolicy、PodSecurityPolicy(或其替代方案)等机制可以实现多租户隔离、权限控制与网络层面的访问限制。Secrets与ConfigMap提供了配置与敏感信息的集中管理方式,但在生产环境中仍建议结合专门的密钥管理系统以获得更强的审计与生命周期管理能力。 Kubernetes的生态极为丰富,Helm作为包管理工具大幅降低了复杂应用的部署门槛,Prometheus与Grafana为监控与告警提供标准化方案,Fluentd与Elasticsearch为日志收集与检索提供支持。对于需要更细致流量控制和安全策略的团队,服务网格与策略引擎的结合能实现零信任架构与细粒度治理。
Operator生态则把领域知识编码为控制回路,使得状态ful服务的自动化运维成为可能。 在实际应用场景中,Kubernetes最常见的价值体现在微服务拆分、弹性伸缩、资源利用率提升与跨环境一致性。团队在从传统虚拟机或物理机环境迁移时,可以通过容器化把运行时依赖与配置标准化,从而在开发、测试与生产环境之间实现一致性,减少"在我机器上能跑"的问题。对于需要弹性扩展的业务,例如电商、内容分发与在线教育平台,Kubernetes能帮助实现自动扩容与流量吸纳,降低因突发流量带来的故障风险。 不过,Kubernetes并非万能。在小规模或简单应用场景下,引入Kubernetes可能带来不必要的复杂度与运维成本。
平台运维需要掌握集群网络、调度策略、存储后端与安全配置等一系列知识,对团队技能要求较高。初期投资包括集群搭建、监控告警、CI/CD集成与运营工具链的建设,这些都需要时间与成本。因此在决定采用Kubernetes时,需要权衡团队规模、业务复杂度与长期演进需求。 多云与混合云部署是Kubernetes另一个重要应用方向。通过一致的API层,Kubernetes能够在不同公有云与私有数据中心之间提供统一的调度语义,降低对单一云供应商的依赖。多集群与联邦方案可以实现跨地域部署与故障域隔离,但也引入了网络延迟、数据一致性与运维复杂度等挑战。
实现真正可靠的多云策略需要在网络互联、数据复制与部署策略上做大量工程化工作。 性能与成本优化是使用Kubernetes必须关注的问题。合理的资源请求与限制、Pod调度策略、节点类型选择及自动伸缩配置,都会显著影响资源利用率与云成本。通过性能分析、容量规划与按需扩缩容策略,可以在保证SLA的同时降低开销。很多团队会结合预留实例、节点池策略与混合节点类型来实现成本优化。 日志、指标与分布式追踪构成了Kubernetes平台的可观测性基石。
Prometheus适合实时指标采集与告警,ELK或OpenSearch适合日志聚合与检索,Jaeger或Zipkin适合分布式调用链追踪。把这些工具与Kubernetes原生监控结合起来,可以实现从单点故障到业务层面影响的快速定位,提高故障恢复效率。 要在企业中成功推广Kubernetes,除了技术能力之外,组织流程与文化的配合也非常关键。微服务设计、DevOps文化、自动化测试与灰度发布策略都需要同步推进。平台团队应当扮演赋能者的角色,为开发团队提供易用的模板、可复用的CI/CD流水线与清晰的运行时约定,从而降低上手门槛并提高平台的采纳率。 学习与落地的建议方面,先从小规模试点开始,选择非关键业务或新项目进行容器化与上云化实践,逐步积累经验。
把基础设施的可观测性、安全策略与自动化部署作为优先事项,避免仅关注功能而忽视运维。结合社区资源与云厂商的托管服务可以显著缩短落地周期,例如使用托管Kubernetes服务来降低集群管理负担。 总结来看,Kubernetes能做的事情远超容器调度本身。它提供了应用部署、弹性伸缩、服务发现、滚动升级、自愈恢复、存储编排、安全治理与多云部署等一整套云原生能力。对于希望实现快速交付、高可用弹性与跨环境一致性的组织,Kubernetes是通往云原生的基石。但是否引入Kubernetes应结合团队规模、业务复杂度与长期技术路线做出权衡,关注初始成本与后续运维投入。
通过渐进式试点、构建可复用的平台能力与完善的监控与安全体系,Kubernetes可以转化为企业持续创新与高效运营的重要引擎。 。