Kubernetes(常简称为 K8s)已经成为现代云原生架构的基石。无论是初创公司还是大型企业,越来越多的团队把容器化应用部署在 Kubernetes 上,以实现自动化调度、弹性伸缩和统一管理。理解 Kubernetes 的核心思想和实践方法,有助于构建可靠、高可用且易于扩展的分布式系统。下面从基础概念、架构组件、应用生命周期、网络与存储、运维与监控、安全与合规、生态工具与落地实践等方面详解 Kubernetes,帮助读者系统掌握并上手生产级部署。Kubernetes 的诞生源于 Google 多年在 Borg 和 Omega 的集群管理实践。作为一个开源容器编排平台,Kubernetes 的目标是将容器化应用抽象为可声明的资源,通过控制循环(control loop)不断对比期望状态与当前状态并做出调整,从而实现自动化部署、伸缩、更新与自愈能力。
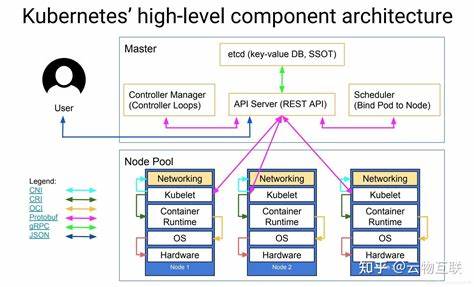
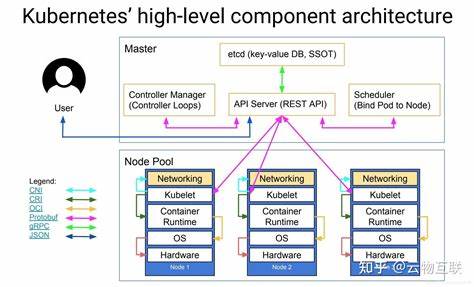
核心概念从宏观到微观包括集群(Cluster)、节点(Node)、Pod、容器(Container)、Deployment、Service、ConfigMap、Secret、PersistentVolume 等。这些概念共同构成了 Kubernetes 的对象模型和控制平面逻辑,使得对应用的管理变得可声明、可复现、可编排。Kubernetes 的控制平面负责全局调度与决策。API Server 是整个系统的入口,所有的改变都通过 API Server 提交。etcd 作为分布式键值存储,保存集群的状态与配置。调度器(Scheduler)负责将待运行的 Pod 分配到合适的节点,调度决策会考虑资源、亲和性、污点与容忍等因素。
控制器管理器(Controller Manager)包含一系列控制器,负责副本管理、节点健康检查、服务端点维护等。节点层面运行 kubelet,它负责与 API Server 通信并管理容器运行时,kube-proxy 负责网络代理与服务转发,容器运行时(如 containerd、CRI-O 或 Docker)负责实际启动容器。Pod 是最小的部署单位,通常包含一个或多个紧密耦合的容器,这些容器共享网络命名空间和存储卷。Deployment 则用于声明无状态应用的期望副本数与更新策略,ReplicaSet 保证期望数量的 Pod 一直运行。StatefulSet 适用于有状态服务,保证 Pod 的唯一标识、顺序启动和稳定存储。DaemonSet 用于在每个节点上运行守护进程。
Job 和 CronJob 用于批处理任务和定时任务。Service 提供对 Pod 的稳定访问入口并支持负载均衡,ClusterIP、NodePort 和 LoadBalancer 是常见的类型。Ingress 提供基于 HTTP/HTTPS 的路由能力,并常与云厂商负载均衡或 Ingress Controller(如 NGINX、Traefik、Contour)配合使用。Kubernetes 的网络模型强调平面地址空间,集群中的每个 Pod 都应当可以通过 IP 直接访问另一个 Pod,无需网络地址转换。CNI(Container Network Interface)插件负责实现网络功能,常见实现包括 Calico、Flannel、Weave、Cilium。网络策略(NetworkPolicy)用于限制 Pod 之间或 Pod 与外部之间的流量,是实现网络隔离与零信任的重要工具。
服务发现与负载均衡依赖于 Service 和 kube-proxy 的工作方式,基于 iptables 或 IPVS 的代理模式在不同规模的集群中表现不同,IPVS 在大规模场景中更高效。存储方面,Kubernetes 将存储抽象为 PersistentVolume(PV)和 PersistentVolumeClaim(PVC)。PV 代表实际的存储资源,可能是本地磁盘、网络存储(如 NFS、iSCSI)、云厂商的块存储或文件存储。StorageClass 用于动态供应 PV,管理员可以定义不同的存储策略和后端。对于有状态服务,StatefulSet 与 PVC 的结合确保每个实例拥有稳定且持久的存储卷。还可以使用 CSI(Container Storage Interface)插件扩展不同存储供应商的能力,实现云上与本地存储的一致管理。
Kubernetes 的应用生命周期管理包括部署、滚动更新、回滚、扩缩容和自愈。Deployment 的滚动更新策略支持逐步替换旧版本 Pod,避免短时间内全部不可用。Horizontal Pod Autoscaler(HPA)和 Vertical Pod Autoscaler(VPA)分别支持基于指标的水平与垂直自动伸缩。Cluster Autoscaler 用于根据调度压力动态调整节点池规模。自愈能力体现在 livenessProbe 与 readinessProbe 的健康检查机制上,Kubernetes 会重启不健康的容器或在容器准备就绪前不将流量转发给它们。在监控与日志领域,Prometheus 已成为 Kubernetes 生态的事实标准,用于采集指标、设置告警并与 Grafana 等做可视化。
日志采集通常采用 Fluentd、Fluent Bit 或 Logstash 将容器日志发送到集中式日志系统如 Elasticsearch 或云日志服务。分布式追踪工具如 Jaeger 或 OpenTelemetry 有助于排查微服务调用链中的性能瓶颈。健壮的监控体系应覆盖节点、容器、网络、存储与应用层指标,并结合告警策略实现及时响应。安全在 Kubernetes 中贯穿多个层面。集群访问控制通常基于 RBAC(Role-Based Access Control),通过 Role 与 ClusterRole 定义权限并将其绑定到用户或服务账户。网络安全通过 NetworkPolicy 与服务网格(Service Mesh,例如 Istio)提供更细粒度的流量控制与加密。
镜像安全需要在 CI/CD 流程中进行镜像扫描并限制使用不可信镜像库。Pod 安全策略(Pod Security Admission)或 OPA Gatekeeper 可以强制执行运行时约束,例如禁止以特权模式运行、限制容器能力与不可写根文件系统。敏感配置建议使用 Secret 管理,但需要注意 Secret 在 etcd 中默认是明文存储,生产环境建议启用 etcd 加密和严格的访问控制。Kubernetes 的生态非常丰富,Helm 作为包管理器简化了应用的打包、管理与发布,提供 Chart 模板化部署。Operators 扩展了 Kubernetes 的控制器模式,将应用逻辑编码为自定义控制循环,使得复杂的有状态应用(如数据库)的运维更易自动化。CRD(Custom Resource Definition)允许创建自定义资源,结合 Operator 可以实现领域特定的自动化。
Service Mesh 为服务间通信引入可观察性、流量控制与安全通信,常见方案有 Istio、Linkerd 和 Consul。CI/CD 与 GitOps 模式在 Kubernetes 上广泛采用,Flux 和 Argo CD 等工具实现声明式的 Git 驱动部署,增加变更可审计性与回滚能力。在实际落地中,企业需要根据业务特点选择合适的部署方式。对于云原生初学者,可以先在本地通过 Minikube、k3s 或 kind 启动小型集群进行功能验证。生产环境通常选择由云厂商托管的 Kubernetes 服务(如 AWS EKS、Google GKE、Azure AKS)以降低运维复杂度,或者在裸金属/私有云上使用 Rancher、OpenShift 等平台做统一管理。混合云与多集群管理是大型组织常见的需求,工具链需要支持集群注册、策略下发、跨集群流量与数据复制。
常见的实践建议包括:在开发阶段尽早容器化并在本地复现集群行为,CI 流程中自动构建并扫描镜像,在测试环境使用真实的卷与网络配置进行集成测试,采用 GitOps 实现配置与部署的可审计变更。资源配额与限额应在 Namespace 级别设定防止"邻居"抢占资源。监控告警应与 SLO/SLI 结合,明确可接受的服务水平。对于数据库等关键有状态服务,评估是否适合在 Kubernetes 中运行,必要时使用托管数据库或专门的操作团队与 Operator 协同管理。常见误区包括把 Kubernetes 视为"万能胶"而忽视应用设计,期望借助平台自动解决所有问题。Kubernetes 强调基础设施自动化,但良好的应用架构仍然关键。
例如,容器应尽量保持无状态,依赖配置与服务发现而非固定 IP。另一个误区是忽视安全与治理,在生产环境中需要从设计阶段就考虑镜像签名、网络隔离、最小权限与审计策略。运维上忽视资源管理和监控会导致节点负载突增或 Pod 不可调度的问题,需通过合理的资源请求与限额、垂直/水平伸缩策略以及节点池管理来缓解。学习 Kubernetes 的路径可以从理解容器与 Docker 开始,掌握基础的容器镜像构建与运行。接着学习 Kubernetes 的核心对象与部署流程,在本地实践创建 Pod、Deployment、Service、ConfigMap 等,并观察它们通过 API Server 的状态变更。之后深入了解调度、存储、网络插件与安全机制,尝试搭建 Prometheus+Grafana 的监控体系以及 Fluentd 的日志收集。
进一步探索 Helm、Operators、Service Mesh 和 GitOps 流程,以提升平台自动化与运维效率。官方文档、Cloud Native Computing Foundation(CNCF)资源和社区博客都是良好的学习渠道,实践与持续迭代是掌握 Kubernetes 的关键。Kubernetes 的优势在于其扩展性与生态成熟度。通过声明式 API 和控制循环,开发和运维可以将更多重复性工作交给平台,同时保持灵活性来支持不同的运行时、网络与存储后端。对于需要弹性扩展、高可用部署和统一运维的团队,Kubernetes 提供了强大的能力。然而,Kubernetes 也有学习曲线和系统复杂性,合理评估引入成本、团队能力与长期运营策略是成功落地的前提。
总结来说,理解 Kubernetes 要从它解决的问题入手:如何在大规模分布式环境中管理容器化应用。掌握核心概念与架构组件,结合网络、存储与安全实践,利用生态工具如 Helm、Operator、Prometheus 与 Service Mesh,可以构建稳健的云原生平台。实践中注重自动化、可观测性与安全治理,逐步从简单的无状态应用扩展到对有状态服务和复杂依赖的生产级支持。通过持续学习和在真实场景中的反复迭代,团队可以把 Kubernetes 打造成提升交付效率与系统可靠性的有效工具。 。