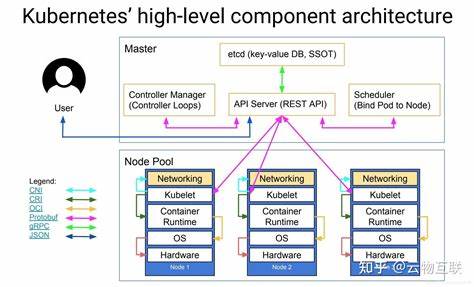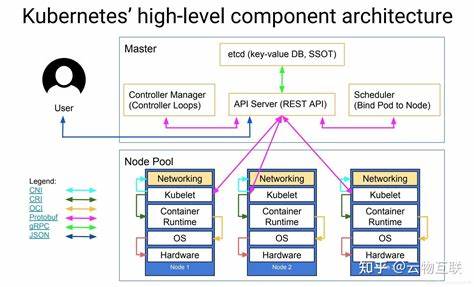
引言 随着大模型在企业应用中的广泛落地,如何在生产级 Kubernetes 集群中可靠、可扩展地部署大模型推理服务成为核心工程问题。vLLM 作为一个面向大规模语言模型推理的开源框架,强调高吞吐、低延迟和内存高效管理。将 vLLM 与 Kubernetes 结合,可以把推理服务纳入已有的容器化 CI/CD、资源调度与运维体系,实现弹性伸缩、统一监控和多团队协作。本文从实战角度出发,覆盖从环境准备到上线运营的关键环节,提供可落地的设计思路和工程注意点,便于在自研或云原生平台上高效交付 vLLM 推理服务。 为何在 Kubernetes 上运行 vLLM Kubernetes 以容器为中心的调度、命名空间隔离、声明式部署和与云生态的兼容性,使其成为承载推理服务的首选平台。在 Kubernetes 上运行 vLLM 可以享受统一的镜像管理、自动重启、滚动升级、以及基于标签和资源配额的多租户隔离。
对 GPU 型工作负载,Kubernetes 支持通过 device plugin 暴露 GPU 资源,结合 CSI 插件能将模型权重放在共享或本地高速存储中,从而兼顾性能与可运维性。 集群与节点准备 部署前需确保集群节点具备合适的 GPU 与驱动环境。生产环境常用 NVIDIA GPU,需安装宿主机驱动并启用 NVIDIA Container Toolkit,使容器可直接使用 GPU。Kubernetes 层面需要部署 NVIDIA device plugin,该插件会在节点上注册 nvidia.com/gpu 等可调度资源。对于支持 MIG 的 GPU(如 A100),可根据吞吐和隔离需求配置 MIG profile。节点的内存、网络、以及 I/O 性能也会显著影响推理性能,建议结合模型规模预估节点的显存与主内存需求,避免频繁的显存溢出或 OOM。
容器镜像与依赖管理 构建 vLLM 的容器镜像时,应以轻量化的基础镜像为起点,确保包含合适的 CUDA、cuDNN 与 Python 包版本,避免在运行时出现 ABI 不兼容问题。建议在镜像中固定依赖版本,并将模型加载逻辑、配置文件与监控埋点打包入镜像。对大模型推理推荐使用多阶段构建减少镜像体积,且把模型权重单独管理为挂载卷或通过外部存储拉取,避免把巨大的权重文件直接打包进镜像。镜像中应包含健康检查接口、日志输出约定以及自动化启动脚本,便于 Kubernetes 的 readiness 与 liveness 探针判断服务状态。 模型权重与存储策略 大模型权重通常体积巨大,直接放在镜像中既不方便更新也会膨胀镜像。推荐使用对象存储(如 S3、MinIO)或分布式文件系统(如 NFS、CephFS)来保存模型权重。
常见做法是在 Pod 启动时通过 initContainer 拉取权重到节点本地的空闲磁盘路径,从而保证模型加载是本地 I/O,降低推理延迟。对带有 NVMe 或本地 SSD 的节点,可以把权重缓存到本地磁盘以获得最佳性能。使用 CSI 驱动将存储卷以 PV/PVC 的形式挂载到 Pod,便于在 Kubernetes 中进行声明式管理与权限控制。 vLLM 服务进程设计 在容器中运行 vLLM 时,建议封装为一个长期运行的推理进程,暴露 HTTP/gRPC 接口供上层业务调用。服务需要实现异步请求队列与高效批处理策略,使得短请求和长上下文共存时仍能保持高吞吐。合理的 batching 参数、最大批大小与超时策略可以在延迟与吞吐之间达成平衡。
服务应支持多种模型来源,例如 Hugging Face 存储、S3 或本地路径,并提供动态加载或热更能力,方便在不中断服务的情况下切换模型或版本。 Kubernetes 部署模式与资源声明 vLLM 推理服务可以以 Deployment、StatefulSet 或 DaemonSet 的形式部署,选择取决于访问模式与数据本地性需求。对于无状态的推理服务,Deployment 是常见选择,便于弹性伸缩和滚动升级。若需要保证每个节点都有本地模型缓存,则可考虑 DaemonSet。资源申请中需显式请求 nvidia.com/gpu 资源,并为 CPU、内存和临时存储设置合理的 request 与 limit。注意 GPU 资源在 Kubernetes 中通常作为不可拆分的大块分配,需按节点 GPU 数量与容器需求设计排期策略。
流量管理与服务暴露 为保证外部请求能稳定访问 vLLM 服务,可在 Kubernetes 中使用 Service 将 Pod 集合统一暴露,并在集群外部使用 Ingress 或 LoadBalancer 类型服务接入。若部署在云环境,利用云厂商的负载均衡器可以方便地实现 TLS 终端和自动扩缩容。对于高并发场景,可在业务侧做请求路由,以路由到不同配置的 vLLM 集群(例如 CPU-only、单卡 GPU、Multi-GPU)。结合 API 网关还能实现鉴权、限流、降级与日志审计功能。 自动伸缩策略 GPU 资源的自动扩缩容在 Kubernetes 中具有挑战性,因为默认 HPA 基于 CPU/内存。可采用自定义指标、Prometheus Adapter 或 KEDA 来驱动基于队列长度、请求延迟或自定义 GPU 利用率的伸缩策略。
另一个思路是结合 Cluster Autoscaler,使节点组在出现无法调度的 GPU 请求时自动扩容。为避免冷启动时间导致体验下降,建议使用预热策略,例如预先保持一定数量的 warm pods 或使用池化节点来减少模型加载带来的延迟。 性能调优实践 性能调优既包括 vLLM 层面的参数,也包括 Kubernetes 层面的资源分配。vLLM 常见的优化手段包括启用混合精度推理、调整 batch 大小、合理设置 max tokens 与缓存策略、以及利用内存映射或分块加载来降低显存峰值。在容器层面,应保证内核参数、进程调度优先级和网络 MTU 设置合理,避免因分页或网络抖动导致性能波动。使用 NUMA 亲和性和 CUDA_VISIBLE_DEVICES 的显卡绑定可以减少跨卡通信开销。
监控显存使用、GPU 利用率与请求延迟,基于数据进行逐步调整。 监控与日志 完善的监控体系对稳定运行至关重要。建议收集 GPU 相关指标(GPU 利用率、显存占用、温度)、主机资源指标(CPU、内存、磁盘 I/O)、Pod 层面指标(请求延迟、错误率、队列长度)以及应用指标(每秒请求数、批次大小分布)。常用方案是部署 node-exporter、Prometheus、Grafana,以及 NVIDIA DCGM exporter 来采集 GPU 数据。日志方面,让容器输出结构化日志,配合 Fluentd 或 Loki 等集中式日志收集系统,方便故障溯源与性能分析。 安全与多租户隔离 在生产环境应严格控制模型与推理接口的访问权限。
利用 Kubernetes 的 RBAC 与 NetworkPolicy 限制谁可以部署或访问推理服务。对模型权重和秘钥采用 Kubernetes Secret 或云厂商的密钥管理服务进行加密存储与访问控制。多租户情况下,为避免单租户占满 GPU 资源,可通过命名空间配额、节点标签与容器级资源限制实现隔离。必要时采用硬件级隔离(如 MIG)或逻辑隔离策略来保证不同租户的服务质量。 CI/CD 与版本管理 将 vLLM 推理服务纳入 CI/CD 流程,可以实现自动构建、自动测试与自动部署。镜像构建应包括单元测试与集成测试阶段,部署前在测试集群做性能基准测试。
模型版本管理同样重要,建议在模型元数据中记录版本号、哈希与来源,并在部署时将版本信息注入到环境变量或配置文件,便于回滚与审计。逐步灰度发布与金丝雀部署可以在升级模型或代码时降低风险。 常见故障与排查建议 在推理服务中常见问题包括显存不足导致的 OOM、模型加载时间过长、非预期的延迟峰值、以及请求丢失。遇到显存问题时,首先检查模型大小、batch 策略与混合精度设置;必要时减少并发或启用分片机制。模型加载慢通常与网络下载或磁盘 I/O 有关,采用本地缓存或预拉取可以显著改善。延迟抖动可能源于垃圾回收、交换分区使用或突发的资源争抢,建议通过资源限制、节点亲和性与探针设置来减少干扰。
成本优化 GPU 是推理系统中最昂贵的资源。通过合理的弹性伸缩、混合实例类型(大卡+小卡)、模型量化与半精度推理可以降低成本。同时,采用请求合并与批处理提升单卡吞吐,减少单位推理的成本。对低优先级或离线推理工作负载,考虑使用 Spot 实例或可抢占实例来进一步节约支出,但需设计容错与重试机制。 总结与落地建议 在 Kubernetes 集群中部署 vLLM 需要在性能、可靠性与可运维性之间做平衡。优先保障稳定的 GPU 与驱动环境,使用对象存储与本地缓存来管理模型权重,将推理服务设计为长期运行的高效进程并暴露标准化接口。
结合自定义指标驱动的自动伸缩、集中化监控与日志、严格的安全隔离以及成熟的 CI/CD 流程,可以把 vLLM 推理服务可靠地纳入生产体系。最后,持续的性能测试与数据驱动的调优是保持系统长期高效运行的关键。 扩展阅读与下一步 在完成基础部署后,可以进一步探索模型并行与流水线并发以支持更巨大的模型,研究基于 MIG 的多租户资源隔离策略,以及引入更智能的请求路由与缓存层来进一步提升服务质量。随着开源推理生态不断演进,保持对 vLLM 与相关工具链的关注,将帮助团队在成本和性能上持续优化。 。