阅读 Kubernetes 源码最重要的不是一口气把所有文件看完,而是找到合适的切入点并建立可重复的探索方法。Kubernetes 代码量大、组件多、抽象层次深,如果没有策略很容易迷失在包与函数之中。建议先明确目标,是要理解调度原理、掌握 kubelet 的 Pod 生命周期、还是改进 API 或贡献 Bug 修复。明确目标后再选择对应的模块和阅读路径,可以把耗费的精力聚焦到最有价值的地方。 搭建本地源码环境是第一步。克隆官方仓库 kubernetes/kubernetes,并熟悉仓库结构。
重要目录包括 cmd 下的可执行文件入口,例如 kube-apiserver、kube-controller-manager、kubelet 等,pkg 下的核心实现,staging 下的模块化 api、apimachinery 与 client-go,vendor 或 go mod 用于依赖管理。建议使用 Go 版本与仓库 README 或官方文档推荐的版本一致。使用 go mod vendor 的项目可能会有 vendor 目录,注意区分 vendor 与 staging 的区别。构建与本地调试可通过 make、bazel 或 Go 自有工具完成。在本地启动集群用于验证改动,可使用 kind、minikube 或 hack/local-up-cluster.sh 等脚本快速搭建测试环境。 选择切入点时,可以采用从上到下或从下到上两种阅读策略。
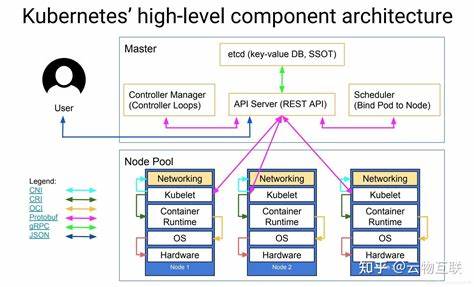
上到下适用于想理解请求流和控制循环的读者,从 kubectl 发起请求开始,依次跟踪到 apiserver、etcd、controller-manager、scheduler 与 kubelet。下到上适用于想理解底层实现的读者,从 util、apimachinery、runtime 等基础包开始,逐步看上层如何调用。无论采用哪种策略,都应遵循一个实用原则:跟随一条具体的请求或场景,把离散的代码片段串成可理解的流程。例如模拟创建一个 Pod,使用更高的日志级别运行 kubectl 并在 apiserver、scheduler、kubelet 中追踪相关日志与函数调用,这样可以把抽象概念映射到具体实现。 理解 Kubernetes 的核心架构和责任分工非常关键。API 层由 kube-apiserver 提供 RESTful 接口,并将持久化交给 etcd。
apiserver 同时负责认证授权、准入控制和版本转换。控制循环模式体现在 controller-manager 中,每个 controller 负责一个资源的期望状态与实际状态对齐。调度器负责 Pod 的调度决策,接收未被调度的 Pod,计算节点优选并绑定。kubelet 在节点上负责 Pod 的生命周期管理、容器运行时交互与状态汇报。掌握这些职责后,查看对应目录的源代码会更有方向感。例如想了解调度,可以从 pkg/scheduler 或 ./staging/src/k8s.io/kube-scheduler 开始;想看容器运行时交互则关注 kubelet/pkg/kubelet/cri 或 dockershim(已弃用但重要历史实现)。
熟悉几类关键代码对象将极大提升阅读效率。首先是 API 类型定义,位于 staging/src/k8s.io/api,掌握核心资源的字段一目了然。其次是 client-go,这里体现了如何以客户端方式和 apiserver 交互,理解 informer、cache、workqueue、listers 等组件对理解控制循环至关重要。Informer 机制是控制器模式的核心,阅读典型控制器的实现可以迅速理解事件通知、队列处理和重试逻辑。控制器一般遵循获取对象-计算期望状态-执行操作-更新状态的循环,阅读同步处理函数和重试策略能快速抓住重点。 阅读代码时要善用测试代码与示例。
单元测试、集成测试和 e2e 测试不仅验证功能,还常常展示代码的使用方式和边界条件。很多实现细节在测试中比在主逻辑里更容易理解。可以把测试作为运行示例,用 go test 在本地调试运行,结合调试器查看堆栈和变量。阅读历史提交和 PR 讨论也能帮助理解为什么以某种方式实现。GitHub 上相关 issue、PR 的描述、代码评审意见和设计文档(design proposals)通常包含实现权衡与替代方案,是快速理解的宝贵资源。 掌握适合的工具能显著提升源码阅读体验。
高效的全文搜索工具如 ripgrep 能快速定位关键符号和用法。利用 Go 的工具链如 go list、go vet、go test 有助于定位包依赖和运行测试。IDE 推荐使用 GoLand 或 VSCode 配合 Go 插件,提供跳转到定义、查找引用和代码导航功能。ctags、godef、godebug 等也很有用。调试器 delve 能在运行时断点检查变量,结合日志可以逐步推进。性能分析工具如 pprof 与 go tool trace 可用于分析 CPU 和内存热点,帮助在源码层面理解性能瓶颈。
调试和可观测性是理解动态行为的关键。Kubernetes 的组件都暴露丰富的日志和指标。启动时指定较高的日志级别,例如 --v=6 或更高,可以看到详细的执行步骤。apiserver 和 kubelet 提供的 metrics 在 Prometheus 格式下帮助理解运行时统计。使用 kubectl describe、kubectl get events 与 kubectl logs 可在集群层面观察资源状态。对于复杂问题,启用 pprof 或运行带有探针的二进制进行性能剖析,可以从调用关系图和堆栈信息更深入地理解代码路径。
阅读 Kubernetes 源码还要理解 Go 语言相关习惯和并发模型。Kubernetes 广泛使用接口和依赖注入模式,读代码时要解开接口实现链,找到具体实现。goroutine 和 channel 的使用非常普遍,关注 goroutine 的生命周期、退出条件和同步机制可以避免误解代码行为。常见并发模式包括 worker pool、rate limiting queue、leader election 等,掌握这些模式能够在不同组件之间迁移阅读经验。 如何有效定位学习目标并逐步贡献是很多工程师关心的问题。建议从容易验证的小改动开始,例如修复一个文档、改进日志信息或优化单元测试。
很多仓库有 good first issue 或 help wanted 标记,适合初次贡献者。提交 PR 前请遵循贡献指南和代码风格要求,运行本地测试和 linters,确保变更不会引入回归。通过小步提交、参与代码评审和回应反馈,既能学习项目的审查标准,也能逐步获得社区信任。 与社区互动是加速理解的重要途径。加入 Kubernetes 的 SIG 与工作组,参与例会或邮件列表可以听到设计讨论与长期路线。GitHub 的 issue 与 PR 记录是解读实现动机的重要窗口。
通过提问、参与讨论或在 Slack/IRC 与维护者沟通,能更快理解某段代码为何如此实现以及未来可能的演变方向。阅读 KEP(Kubernetes Enhancement Proposals)和设计文档能把握功能从提出到实现的全过程。 实际阅读过程中可以采用一种可复用的笔记方法。每次阅读一个功能或模块时,用一个文档记录该功能的业务目标、关键数据结构、主要控制流、典型入口点和常见异常场景。同时记录与之相关的测试文件、benchmarks 与历史 PR。这样在下次研究相关问题时,能够快速回溯并继续深化。
随着时间积累,你会形成个人的知识地图,覆盖 API 流程、控制器模式、调度逻辑和节点代理实现等核心区域。 最后,保持耐心与持续学习的心态非常重要。Kubernetes 项目在不断发展,API 版本迭代、模块重构和性能优化时有发生。定期阅读 release notes、CHANGELOG 和设计提案可以跟踪项目演进。通过小范围的改动与多次迭代,你会逐步把零碎的理解连接成系统性的知识。阅读源码不仅是技术能力的培养,也是一种理解分布式系统设计思想与工程权衡的过程。
跟随一条请求、跑通一个生命周期、修复一个 bug,这样的实战会让理论知识真正成为可复用的实践能力。祝你在 Kubernetes 源码的探索之路上越走越顺,并通过贡献将经验回馈给社区。 。