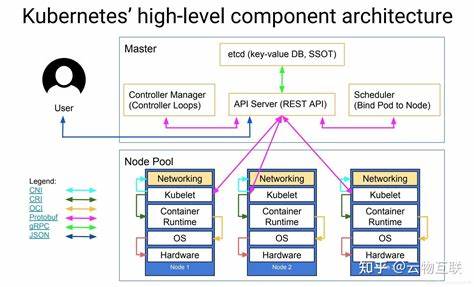
Kubernetes在云原生时代被广泛认可为容器编排的事实性标准,但在生产环境中,随之而来的复杂性常常成为工程组织的绊脚石。集群组件众多、网络与存储的多样性、CRD与Operator的生态、以及日常升级与故障恢复都让团队花费大量时间在运维细节上,而非业务创新。要解决Kubernetes在生产中使用过于复杂的问题,需要从技术、流程和组织三方面系统性地化繁为简,打造可重复、可观测、可演进的平台能力。下面针对常见痛点提供可落地的实践与思路。 首先要回到为什么使用Kubernetes的初衷。明确使用Kubernetes是为了解决应用部署一致性、弹性伸缩与资源隔离等问题,而不是为了追求最新的技术潮流。
基于这一原则,可以通过减少Kubernetes的"可选项"来降低认知负担。为团队提供一套意见化的技术栈与模板,明确首选方案,例如规定网络插件、Ingress实现、持久化存储方案、日志与监控方案等,避免每个团队自行选择导致的碎片化与运维复杂性。意见化并不等于强制僵化,而是给出默认路径,并在确有特殊需求时提供评审机制。 平台化是化简Kubernetes复杂性的核心手段之一。把重复的运维工作上移为平台服务,变成开发者可自助使用的API或界面,典型做法是把集群管理、命名空间生命周期、服务注册、CI/CD流水线等封装成内部PaaS或平台团队提供的Catalog。这样开发团队只需关注应用清单与部署规范,而不必了解底层调度或网络细节。
平台化还应包含成本与配额管理、标准镜像仓库和安全加固模板,保障一致性并降低出错概率。构建平台时建议采用小步迭代,先解决最痛的几类场景,再逐步扩展覆盖面,避免一次性覆盖所有需求导致交付拖延。 自动化与GitOps实践是降低人为错误和提升可重复性的关键。通过把集群配置与应用清单纳入版本控制,配合自动化同步工具,变更获得可审计、可回滚的特性。CI/CD流水线尽可能标准化,治理部署策略、镜像签名、镜像扫描与安全扫描纳入流水线,减少上线过程中的手动步骤。自动化还应覆盖故障演练与备份恢复流程,定期演练集群升级与灾难切换,保证在真实故障发生时团队能有明确的应对流程。
可观测性是治理复杂性的另一把利器。没有可观测性,复杂系统的故障定位往往需要耗费大量时间。为Kubernetes平台构建统一的监控、日志与分布式追踪方案,确保集群健康、节点资源、Pod生命周期、网络延迟等指标可视化。告警规则应与SLO/SLA绑定,避免告警泛滥导致疲劳。在日志收集与追踪方面,采用结构化日志、统一ingest管道与采样策略,有助于快速定位跨服务的问题。将观测数据作为平台的第一等公民,支持基于指标的容量规划与成本分析。
安全与合规性不应成为复杂性的附属品,而应被设计为平台的一部分。采用策略即代码的方式,通过Admission Controller、OPA/Gatekeeper、PodSecurityPolicy或替代方案实现策略执行,对镜像来源、特权容器、网络策略、Secret管理等进行集中治理。强制实施最小权限原则并结合服务账户与RBAC细化权限边界。对于敏感数据的存储和访问,建议使用经审计的秘密管理解决方案,并避免在YAML中明文存放凭证。安全策略与自动化扫描相结合,能在CI阶段阻止危险配置进入生产。 成本治理是很多团队忽视但实际产生巨大价值的环节。
Kubernetes的弹性与丰富资源类型容易导致浪费。通过配额、资源请求与限制、自动伸缩策略以及节点池划分来控制成本。引入成本中心与标签策略,让每个业务单元可以清晰看到其资源消耗。使用Spot/抢占式实例结合冗余部署可以显著降低计算成本,但需做好容错与重启策略。成本优化应与SLO目标权衡,避免过度追求成本削减而影响可靠性。 简化运维的另一个有效方法是采用托管Kubernetes服务。
公有云的托管服务如GKE、EKS、AKS在集群控制面、节点管理与升级方面提供大量托管能力,减少自建控制面的运维负担。托管服务并非万能,仍需注意版本兼容性、网络拓扑与供应商锁定风险,但对资源有限的团队和初期落地的场景来说,托管服务能快速降低门槛并释放团队精力到应用开发上。对于有合规或高定制需求的组织,可以采用混合策略,将控制面托管与部分关键工作负载运行在自管集群中。 对于复杂的生态组件如Service Mesh、Operator、CRD的使用应慎之又慎。Service Mesh可带来流量管理、熔断、监控和安全功能,但也会增加延迟、运维复杂性和学习成本。建议先评估是否可以仅用Ingress控制器、API网关与Sidecar模式以外的轻量方案满足需求,再逐步引入Service Mesh并从少量关键服务开始试点。
CRD与Operator在自动化运维方面能力强大,但滥用会导致集群中出现难以统一治理的自定义资源。对每个引入的组件制定生命周期规则,明确谁负责升级、备份与故障排查,防止"幽灵组件"悄然增加运维负担。 团队能力与文化是化简Kubernetes复杂性的根本因素。技术平台再好也需要正确的组织配合。推动平台即产品的思维,把平台团队定位为内部服务的产品方,建立清晰的SLA、用户反馈渠道与Roadmap。培养开发者的自助能力,但同时提供充足的文档、标准化的模板与培训。
实施变更时采用逐步上线与灰度发布,减少大规模变更导致的震荡。对于关键知识点建立知识库与Runbook,让新成员能够快速上手。SRE实践与"错误预算"机制可以帮助团队在可靠性与交付速度之间找到平衡。 在集群生命周期管理方面,制定明确的升级策略与回滚方案。集群升级应循序渐进,先在非生产环境进行全量演练,然后分批升级生产集群。维护多个版本的兼容性测试用例以及演练脚本可以显著降低升级引发的风险。
备份策略要覆盖etcd、卷快照与重要配置,定期验证恢复过程。对于多集群场景,考虑采用集中管理平面或多集群控制工具来做统一视图与策略下发,避免各集群走向各自为政。 最后需要回答一个实际而重要的问题:是否必须在所有场景下使用Kubernetes。答案是否定的。小型服务或简单任务调度并不总需要Kubernetes的全部能力,Serverless、托管容器平台或Platform-as-a-Service在很多场景下能以更低的复杂性实现更高的开发效率。评估成本与收益,在适当的时候采用更轻量的方案,同样是化繁为简的一种智慧。
对于决定长期使用Kubernetes的团队,要确保从一开始就把平台化、自动化与治理纳入规划,将复杂性以结构化方式管理,而不是任其自然增长。 总之,化解Kubernetes在生产环境中的复杂性不是一次性技术改造,而是一系列策略性选择的组合。通过意见化的技术栈、平台化服务、GitOps与自动化、完善的可观测性与安全治理、合理的成本控制以及健康的组织文化,可以把Kubernetes从一堆不确定因素转变为可控的生产力工具。真正成功的实践往往是渐进的,以用户痛点为牵引,先解决最关键的几个问题,然后将成熟的做法沉淀成平台能力,让开发者与运维都能在可控的复杂性中高效协作。 。