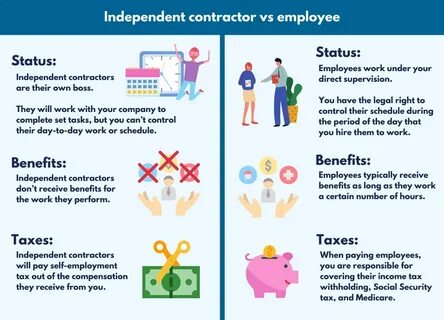
在现代数据分析与科学研究中,常常有人试图通过“控制”其他变量来揭示某一变量对结果的因果影响。乍看之下,这种做法似乎理所当然且直观——只要调整了相关因素,其余变量影响被“控制”住,X对Y的效应就能被准确测量。然而,现实远比这个简单。如果没有扎实的因果理论支撑,单纯将若干变量作为控制变量投入回归模型,轻易得出的因果推论极有可能误导读者,甚至得出完全错误的结论。要真正理解控制变量为何不能轻率使用,必须先弄清楚变量之间复杂的因果关系网络。比如,我们经常碰到的混淆变量、中介变量和碰撞变量(collider)各不相同,错误识别和调整这些变量会带来截然不同的后果。
假设我们想研究变量X对变量Y的因果效应,但存在一个变量C,它既影响X也影响Y,这正是典型的混淆变量。此时,如果不控制变量C,X和Y之间的关系就会被C干扰,导致估计偏差。理论上,利用控制变量C可以部分剥离这个偏差,从而更接近真实的因果效应。然而,控制混淆变量的前提是准确识别它的因果角色,并且测量该变量时必须足够精准。测量误差和代理变量的采用都会影响控制效果,甚至引入新的误差。更复杂的是碰撞变量的情形。
碰撞变量不同于混淆变量,它是由X和Y共同影响的变量。当我们控制一个碰撞变量时,原本不存在的虚假关联会在X和Y之间“显现”,产生假相关,这种现象被称为碰撞偏差。典型案例包括疫情中年龄和感染状态同时影响样本选择的自愿数据收集,从而在样本中引发虚假的关联。此外,中介变量的情况常常被忽略。中介变量是被X影响而进一步影响Y的变量。如果在分析中控制了中介变量,相当于阻断了X通过该中介对Y的间接效应,得到的结果反而是不完整的“净效应”,难以代表X的总因果影响。
现实中的因果关系网络极为复杂,一个变量可能既是混淆变量也是中介变量,甚至同时充当多重角色,这让简单的控制策略难以适用。变量本身的测量不准确也令人头疼。比如收入、性格特质或智商等变量,即使被广泛用作控制变量,也往往测量不稳,可靠性可能很低,更不用说代理变量的使用可能偏离所需衡量的真实概念。测量误差不仅降低控制效率,还可能使得研究者陷入虚假的安全感,误判因果路径。另一个沉重的现实是匹配方法大多无法解决残余混淆。许多研究试图通过匹配让对照组和处理组在潜在混淆因素上相似,进而推断因果效应,但如果匹配基于的变量不充分或测量不够精确,残留的混淆将依然影响结果。
著名的Facebook大规模社交行为研究展示了即使使用了数千个变量进行控制,观察性研究估计的偏误依旧巨大。大量数据和复杂控制虽然能部分缓解问题,但依然无法保证因果推断的准确性。更糟糕的是,过度控制也常成为误区。在一些情境中,控制变量过多、变量间高度相关,会引发多重共线性,导致分析数值不稳定、解释混乱,甚至得不到合理结论。过度控制一个变量,可能会“剥夺”掉本应保留的效应,让结果失去现实意义。经典例子如将麦当劳和米其林三星餐厅进行比较时,过度控制了他们存在差异的所有特质,结果反倒得出“二者无异”的荒谬结论。
这种现象警示我们,控制变量选择必须精炼、理论驱动,而不是无序叠加。针对控制的局限性,研究设计层面提出了其他思路。天然实验和准实验设计通过自然随机性或制度变革等方式,尝试打破因果链上的混淆,获得更可靠的因果估计。例如用彩票中奖作为财富的随机化来源,评估财富对政治观点的因果影响,又如双生子研究有效去除遗传和环境混淆。但这些设计也非完美,识别威胁依然存在,需结合深厚的理论背景和扎实的质性理解。例如非随机的工具变量分配或工具变量本身作用不明确,都会削弱因果推断的可信度。
即便进入实验研究领域,控制问题依旧需要谨慎。实验随机化理论上能解决混淆问题,但若实验设计或执行出现问题,如缺乏盲法、对照组设置不合理、样本受骚扰等,也会影响结果真实性。更重要的是对照组类型——被动对照组还是主动对照组——会显著影响干预效应的估计,有时用简单的安慰剂或虚假干预作为对照才是更科学的选择。尤其是在认知训练或心理干预等领域,研究显示使用主动对照组时,正面效果往往比采用被动对照组时大幅度下降。归根结底,统计控制不是机械的公式应用,而是一场严肃的科学推理活动。随意添加控制变量而不思考其因果地位,容易陷入碰撞偏差、中介偏差和测量误差的泥潭。
每一个控制决策,都需要基于详细的因果模型、扎实的理论证据和数据质量考量。正如因果推断大师Judea Pearl在《因果之书》中强调,理解因果关系需要结构化的因果图模型和干预理论,仅有数据关联是远远不够的。科学探索的魅力正来源于掌握了如何绕过复杂迷宫般的变量纠结,洞悉底层真正的因果联系。仅有数学手段,不思考变量背后的因果机制,只会得出表面看似合理却误导性的结论。控制变量的故事提醒我们,科学研究中的“控制”不仅是数字上的调整,更是求真务实的思辨。掌握好控制的艺术,是真正做到科学严谨和可信因果推断的关键一步。
。