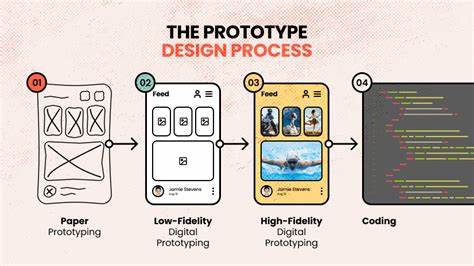
随着摄影设备的普及与计算能力的飞速提升,图像质量优化不再局限于单帧处理。ImageMM作为一种联结多帧图像恢复与超分辨率的综合框架,应运而生,成为提升低质视频与模糊照片视觉体验的重要手段。多帧方法通过从相邻帧中提取互补信息,弥补单帧固有信息匮乏的问题,为去噪、去模糊、缺失细节重建和分辨率提升提供了更丰富的线索。理解ImageMM的原理与实践,对于研究人员、工程师乃至应用开发者都具有重要价值。多帧图像恢复的核心挑战来源于场景动态性和摄像机运动。相邻帧虽然包含重复和互补内容,但由于物体运动、视角变化、光照波动以及压缩伪影,直接对齐与融合并非易事。
传统方法依赖光流或特征匹配来实现像素级对齐,但这些方法在低光或噪声环境下鲁棒性不足。ImageMM提出了联合处理框架,将对齐、补偿、融合与超分辨率作为一个端到端可学习的过程,从而在面对真实世界复杂扰动时表现出更好的稳健性。在技术实现上,ImageMM通常包含四个关键模块:运动估计与对齐、特征提取、时空融合与增强、以及高分辨率重建。运动估计可以采用经典的光流方法,也可以引入基于深度学习的网络,例如使用PWC-Net或基于Transformer的自注意力网络来捕捉长程依赖。对齐模块不仅仅是几何变换,而是通过隐式对齐策略学习如何在特征域中匹配信息,从而降低对精确光流的依赖。特征提取阶段用卷积神经网络或混合卷积-注意力结构提取多尺度语义与纹理信息,为后续融合提供更稳定的表示。
时空融合是ImageMM的核心创新点之一。不同帧包含的细节可能相互覆盖或互补,合理的融合策略决定了最终效果。早期方法通过简单的加权平均或光流引导的像素融合实现信息聚合,但无法充分利用帧间相关性。现代方案采用基于注意力的加权机制,通过学习帧间权重自适应聚合可靠信息,抑制运动伪影与噪声传播。某些模型还引入时间滤波或递归结构来实现长期依赖建模,使重建结果在时间序列上更平滑、一致。高分辨率重建阶段则侧重于细节恢复与视觉质量提升。
除了常见的像素重建损失外,ImageMM常结合感知损失、对抗训练与特征匹配损失,以兼顾客观指标与主观视觉效果。感知损失基于预训练网络的高层特征距离,促使生成结果在语义层面逼近高质量真值;对抗训练进一步提升纹理真实感,但需要在稳定性与伪影风险之间取得平衡。为了避免时间上抖动或局部不一致,模型训练过程中也会加入时序一致性约束或光流一致性损失。数据与训练策略直接影响ImageMM的泛化能力。高质量带标签的多帧数据难以获取,特别是在真实拍摄的模糊、噪声场景下。因此常用合成数据与真实数据混合训练,并采用域适应或自监督方法缩小模拟与真实之间的差距。
自监督策略例如基于帧间重建的二次重投影损失、遮挡感知的对比学习等,能在无标签情况下提高模型对动态场景的健壮性。数据增强技术也被广泛应用,通过模拟多种噪声、运动模糊、压缩伪影来提升模型对复杂场景的鲁棒性。在模型架构方面,近年来的研究趋势呈现融合卷积与Transformer优势的方向。卷积擅长局部纹理建模与计算效率,Transformer凭借全局自注意力能更好地处理长程帧间关联。ImageMM常采用分支式设计,一部分负责局部细节提取,另一部分通过跨帧自注意力机制实现信息跨越时间轴的聚合。这样的混合结构在提升重建质量的同时,也能控制参数规模,使得模型在边缘设备上具备可部署性。
评估指标方面,传统上以PSNR和SSIM衡量重建的像素准确度与结构保真度,但它们并不能完全反映人眼的感知质量。LPIPS等感知度量和用户主观评分在评估超分辨率与恢复质量时越来越重要。对于视频或多帧场景,时间一致性指标也不可忽视。模型在单帧指标上表现优异却可能在连续帧中产生闪烁或纹理不稳定,这对实际应用影响极大。因此在优化目标中融入时间一致性和视觉连续性是衡量优劣的关键。ImageMM的应用场景非常广泛。
智能手机摄影利用多帧融合在弱光环境下提升细节与降低噪声,许多商业相机系统已经将多帧超分辨率纳入拍摄流水线。视频增强与流媒体服务通过多帧恢复技术在低码率下恢复细节,提升用户观看体验。安防监控领域对远距离、人脸识别场景的清晰度要求迫使多帧超分辨率成为提升可识别性的有效手段。医学影像与天文观测等专业领域也从多帧重复采样中获益,通过融合多次观测降低噪声并重建微弱信号。尽管优势明显,ImageMM在实际部署中仍面临约束。实时性与计算资源是主要瓶颈之一。
高性能模型往往参数量大、计算复杂度高,在移动设备或嵌入式系统上难以满足低延迟要求。为此轻量级网络设计、模型剪枝、量化以及基于知识蒸馏的加速方法被广泛研究。硬件协同优化例如利用NPU、GPU加速和张量核心运算可以显著提升推理效率。另一个挑战是对运动和遮挡的鲁棒性。在复杂遮挡或极端运动情况下,错误的对齐可能导致跨帧伪影。有效的遮挡检测、鲁棒的信息选择和自适应融合机制是缓解这类问题的关键。
未来发展方向值得关注。首先,无监督与自监督方法将进一步推动模型在真实场景下的泛化能力,减少对昂贵标注数据的依赖。其次,将生成式模型与明确物理模型相结合,可能在保真度与感知质量之间找到更优平衡。第三,跨模态融合例如将多光谱、深度或雷达信息与可见光帧联合使用,为特定应用场景(如遥感或医学)带来更可靠的恢复能力。另一个重要趋势是视频级别的长期一致性保障,避免在长时序中出现累积误差或闪烁现象。研究者与工程师在采用ImageMM时,应重视问题设定与评估场景的匹配。
若目标是最大化像素级指标,偏向基于L1/L2的回归损失与精细对齐策略;若目标是主观视觉质量或面向最终用户体验,则应更多采用感知损失、对抗训练与主观评测。部署阶段需要在模型复杂度与实时性之间权衡,结合硬件能力选择合适的加速方案与压缩策略。数据方面,收集高质量、多场景、多噪声类型的训练样本,并利用合成与真实混合训练策略,有助于提升模型在野外环境的表现。总体来看,ImageMM作为多帧图像恢复与超分辨率的联合框架,代表了图像增强领域从单帧向时空协同处理转变的时代潮流。通过对运动理解、跨帧信息融合与感知级优化的有机结合,ImageMM不仅能在传统指标上带来提升,更能显著改善主观视觉体验。随着模型架构、无监督学习和硬件协同优化的进步,多帧恢复技术将在更广泛的应用场景中发挥变革性作用,让低质量输入也能重现细节与真实感。
对于从事图像处理与计算摄影的开发者与研究者而言,深入掌握ImageMM的设计思想与工程实践,将为构建下一代视觉增强系统奠定坚实基础。 。