随着人工智能领域的发展和模型规模的不断膨胀,如何有效提升大规模模型的训练效率成为科研和工业界的焦点。尤其是在预训练阶段,由于计算量巨大,训练速度的提升直接影响到模型的迭代周期和应用落地速度。最近在大型GPU集群上,研究人员通过结合TorchAO框架、MXFP8数据类型以及TorchTitan优化策略,成功实现了2K规模预训练过程的加速,最高达到1.28倍提升,为深度学习训练带来了新的效率革命。 TorchAO作为PyTorch生态中一款专注于自动微分和加速的开源框架,在本次实验中扮演了关键角色。其对新兴低精度数据类型的支持极大地优化了计算资源的利用率,而MXFP8作为一种创新的8位浮点数格式,在硬件层面得到了NVIDIA新一代Blackwell架构的支持。相比传统的BF16格式,MXFP8采用更细粒度的缩放因子管理策略,将量化的控制精度提升到了每32个元素一个缩放因子,这种设计不仅保证了数据表达的精度还有效减少了计算开销,提升了数据吞吐率。
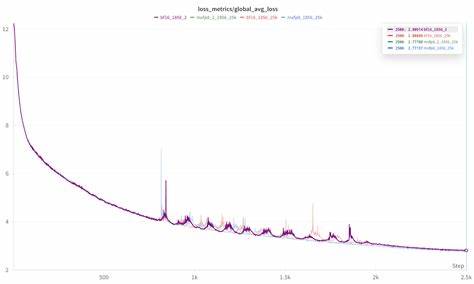
实验所用的Crusoe B200集群拥有高达1856个GPU,借助这一规模庞大的计算资源,研究团队验证了MXFP8与TorchAO结合应用的可行性及性能优势。经过多轮训练测试,结果显示使用MXFP8数据类型在训练速度方面相较BF16提升了约22%到28%之间,且在各个规模下均能保证模型损失曲线的收敛效果与传统BF16训练持平甚至略有超越。 这一成果的实现得益于MXFP8独特的量化机制。传统低精度训练往往面临数值稳定性不足、信息表达受限等挑战,特别是在大规模模型训练时更为突出。MXFP8通过细化的缩放因子分配策略,巧妙地平衡了精度与性能的矛盾,使得低精度计算不仅具备速度优势,也能满足对训练精确度的严格要求。此外,MXFP8所采用的E8M0格式缩放因子(即以2的幂为单位的量化方式)进一步简化了硬件实现,提高了运算效率。
TorchTitan则是另一项促进效率提升的重要技术。作为专为Llama3-70B模型优化的训练框架,TorchTitan结合了HSDP2(分层状态数据并行)与Context Parallel(上下文并行)策略,有效地改进了模型在多卡、多节点环境下的通信与内存管理,减少了瓶颈和资源闲置,提高了训练的可扩展性和吞吐能力。在此次加速测试中,通过在Context Parallel=2配置下运行,团队实现了高效的GPU资源利用率,并在保持模型准确度的前提下,极大地缩短了训练时间。 关于扩展性,实验结果尤为令人鼓舞。在节点规模从4台提升至188台的过程中,仅出现约5%的性能衰减,这说明该方案具备极佳的分布式训练扩展能力。多节点环境下,通信效率通常是性能瓶颈,但通过深度优化的TorchAO内核及TorchTitan的并行设计,这些瓶颈得到了显著缓解,使得训练速度稳定提升,且大幅提升了训练集群的整体生产率。
另外,团队还持续优化了关键的内核函数,特别是针对维度1上的数据复制和转换进行了改进。新的dim1casting技术能够更灵活地应对列方向的内存访问模式,减少了因数据布局不合理造成的访问延迟。初步测试显示,基于该优化的12层Transformer模块测试中,训练加速达到了1.31倍,表明未来有望通过软件层面的进一步打磨实现更高效率。 当前的研究虽然聚焦于MXFP8与BF16的性能对比,团队也对未来更低精度的数据格式如MXFP4及NVFP4表现出了浓厚兴趣。基于最新的Quartet论文,这些4位浮点数格式有望提供进一步的计算加速空间,进一步降低内存带宽压力。此外,这些超低精度格式仍需在硬件和软件层面优化以解决精度稳定性等潜在挑战,但它们预示着更加节能高效的深度学习训练新时代。
在大规模人工智能模型训练正快速普及的背景下,提升训练效率不仅能够节省大量算力和能源成本,还能为模型开发者带来更短的研发周期,使得新技术和应用能够更快进入市场。通过TorchAO提供的开放生态体系,开发者能够更方便地实现和部署前沿低精度计算方案,加速模型训练,推动AI技术的迭代。 总结来看,TorchAO与MXFP8的结合,配合TorchTitan的架构优化,构建了一个高效、稳定且具备优异扩展性的训练生态。Crusoe B200集群上的实测数据充分证明了这一方案在实际工程应用中的巨大潜力。未来,随着更多硬件支持和算法优化的到来,低精度训练将成为大规模深度学习的主流趋势,让AI模型在更短时间内获得更强能力,推动产业智能化变革不断升级。 。