在大数据和云计算快速发展的今天,如何高效存储和访问海量的多维数据成为数据科学与工程领域的核心问题之一。二维数组作为多维数据的基础结构,其存储和读取效率直接影响系统性能与用户体验。Vischunk作为一款创新工具,提供了对二维数组分块(chunking)和线性化(linearization)策略的深入分析和互动模拟,帮助用户理解不同设计选择如何影响数据访问的效率,进而优化数据存储方案。随着云存储的普及,尤其是面向对象存储服务如亚马逊S3,理解数据从逻辑结构到物理存储的映射过程变得尤为重要。二维数组本质上是n维数据的一种特殊表现形式,而存储系统需要将这类多维数据线性化为一维以便于在网络上传输和磁盘存储。这种线性化过程本身就埋下了读写性能的隐患。
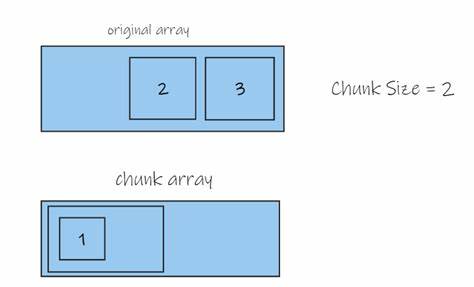
线性化一方面保证了数据在物理媒介上的连续性,另一方面却可能破坏数据在多维空间上的局部性,导致访问模式与存储布局不匹配,从而带来冗余的I/O开销。为了克服这一矛盾,分块技术应运而生。分块将大规模数组划分为若干块状小单元,每个块既作为压缩的单元,也作为数据读取的最小单位。在网络访问环境下,适当的块大小设计至关重要。块太小,会带来请求数量过多及其带来的延迟与管理开销;块太大,则会引发大量无用数据的传输,浪费带宽和时间。Vischunk通过可视化界面展现了不同块大小和线性化算法对读取效率的影响,方便用户直观感受各种策略的优劣。
例如,用户可以设置数组的尺寸、选择块大小,指定块内以及块间的线性化顺序,再通过模拟查询区域观察实际读取的数据量与请求次数。更重要的是,Vischunk还实现了多种经典的线性化方案,包括行优先(row-major)、列优先(column-major)、Z序(Z-order或Morton曲线)和Hilbert曲线。这些算法各自对二维空间局部性保存有不同表现,进而影响读取数据的连续性和合并效率。行优先和列优先线性化方式是最常见的形式,前者适合行方向连续访问的数据工作负载,比如按行遍历矩阵的计算任务;后者则更适合按列倾斜的访问模式,如某些科学计算场景。相较之下,Z序曲线和Hilbert曲线属于空间填充曲线,能够更好地保持二维空间邻近性的后续数据顺序,尤其适用于二维范围查询和空间数据库应用。Hilbert曲线甚至被视为最优的局部性保持策略,但计算复杂度较高。
在分析过程中,Vischunk通过颜色渐变(从绿色到红色)直观地反映了存储中数据访问的先后顺序,蓝色边框则高亮用户的查询范围,白色叠加层显示当前鼠标悬停的位置,极大地方便了理解逻辑与物理映射之间的关系。性能指标方面,Vischunk提供了诸如请求单元数量、实际读取单元数、读取放大倍数(read amplification)、读取效率、涉及块数、读取范围及合并系数等信息。读取放大倍数反映了在实现查询时为了满足数据访问实际需读取的额外数据量,数值越小代表越少冗余;读取效率衡量有效数据占读取总量的百分比,代表实际I/O的利用率。涉及块数量和读取范围则揭示了访问碎片化程度,合并系数显示在多个块读取时I/O请求能够合并的程度,从而减少请求次数,提升整体性能。此外,存储对齐指标综合衡量查询访问与存储布局之间的契合度,帮助用户从全局视角把握最佳策略。基于这些数据反馈,用户可以尝试不同的块大小和线性化方法,针对特定访问模式找到最优解。
例如,面对一个要求频繁读取大范围数据的应用,使用较大的分块和空间填充曲线线性化可能带来更好的带宽利用和延迟表现。相反,点查询密集且分散的场景,微小分块和行或列优先模式则有助于减小数据冗余和响应时间。Vischunk不仅提供了强大直观的模拟环境,还配套了丰富的理论知识介绍和实践建议,帮助用户理解当下分块技术面临的挑战及历史演进。在云数据平台的不断扩张之际,数据科学家、存储架构师和软件工程师们均可从中受益,提升设计决策的科学性和实施效率。总之,Vischunk作为一款结合理论与实践、互动性强的可视化分析工具,在探索二维数组分块与线性化的过程中起到了桥梁作用,使得复杂的存储布局优化问题变得具体且易于把握。未来,随着空间填充曲线研究的深入及分布式存储技术的发展,类似Vischunk这样的工具将帮助更多团队实现对大规模多维数据的高效管理。
数据库系统、地理空间信息服务、科学计算平台等应用领域均可借助此类模拟器,可视化并量化访问模式与存储设计的匹配度,争取更低的读取延迟、更小的网络带宽消耗和更高的系统吞吐率。在数字化转型持续加速的当下,对多维数据的高效处理能力已成为企业竞争力的重要指标,掌握并应用分块与线性化的最佳实践,将助力实现存储与访问架构的持续优化。 。