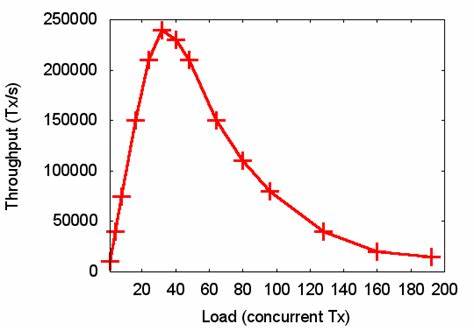
近年来,"第二大脑"成为诸多开发者与知识工作者热议的概念,但当需要同时管理多个项目、学习路径或生活角色时,单一记忆模型常常无法同时记住不同上下文,导致频繁重复说明、效率下降与认知碎片化。Llmswap 应运而生,提出以每项目(per-project)工作区为单位的 AI 持久记忆,让"第二大脑"变成多个独立且可持续演进的记忆体,显著降低上下文切换成本并增强长期学习能力。 Llmswap 的核心理念是把记忆与工作区耦合。用户进入某个目录或项目时,工具会自动加载与该工作区相关的记忆文件,如 context.md、learnings.md、decisions.md,使 AI 在每次会话中拥有连续的背景知识。这种按项目划分的记忆体系,既适合团队协作中的项目约定和企业模式,也适用于个人学习路径与实验记录,能让 AI 真正"记得"你昨天、上周或上个月的讨论要点。 功能层面,Llmswap 提供自动学习日记(auto-learning journals),工具会从每次对话中提取关键信息并组织到学习笔记中,确保经验不会随着会话终结而消失。
多种教学人格(如 Guru、Socrates、Coach)可以切换对话风格,满足不同场景下的教学或辅导需求。平台还强调对上游模型的开放兼容性,支持包括 Claude Sonnet 4.5、IBM Watsonx、GPT-4o、Gemini、Groq、Ollama 等多种 LLM 提供商,配合 Python SDK 与命令行界面,方便集成进开发者现有工作流,同时避免厂商锁定。 在技术实现上,Llmswap 采用本地与云端混合的设计模式。每个工作区的记忆以文本、结构化摘要与向量化嵌入的形式存储,文本记忆用于快速读取上下文,向量化嵌入用于高效的语义检索。用户在本地工作区中保有可读的记忆文件,方便审计与版本控制,同时也可以选择将向量索引推送到受控的向量数据库,以提升跨设备检索性能。记忆抽取模块利用简单的抽象规则与模型驱动的关键信息抽取,将对话归档为"学到的内容"、"作出的决策"和"未解决的问题",便于后续检索与复盘。
与其他市场方案的差异在于工作区本位的思路。许多竞品将记忆当成单一全局知识库,或依赖云端账户维持会话状态,而 Llmswap 则把记忆挂载在项目目录上,天然支持多项目并行的使用模式。对开发者而言,这意味着当你切换文件夹时,AI 会自动切换上下文,不再需要重复介绍 tech stack 或团队约定。对学习者而言,学习路径和痛点会被有条理地记录下来,AI 能基于历史反馈制定更贴合个人节奏的学习建议。 隐私与安全是 Llmswap 设计时的重点考量。默认情况下,记忆文件以明文存储在本地,便于审计与回溯;同时提供加密存储选项(例如通过本地密钥管理或集成操作系统级别的密钥库),以防止非授权访问。
对于需要把索引或部分数据推送到云端的团队,Llmswap 支持端到端加密的传输与访问控制策略,并允许企业自行托管向量数据库或使用支持合规性的云服务。审计日志、变更历史与可回滚的记忆版本有助于满足合规与监管要求。 在实际工作流中,Llmswap 的使用场景多样。软件工程团队可以为每个微服务或仓库保留工作区记忆,记录架构决策、接口约定与性能优化历史;研究者可以为每个课题维护实验日志、失败原因与后续计划,避免重复试错;个人学习者可以将学习目标、难点和教学反馈聚合,让 AI 成为可持续的学习伙伴。团队协作场景下,工作区记忆可以与 Git 流程结合,将重要决策与讨论写入 commit 或 PR 的相关记忆文档,形成结构化的知识传承路径。 为了保证记忆的长期可用性与相关性,Llmswap 引入了记忆维护策略。
自动摘要与跨会话合并能压缩冗余信息,保留关键结论与时间戳。基于使用频率与检索命中的回溯机制会定期重排记忆的重要性,让近期活动更容易被检索到。对于旧的或已过时的信息,系统会标注为"历史决策"或"已弃用",并保留原始来源,保证知识的可追溯性而非盲目删除。 在兼容性方面,Llmswap 的 Python SDK 提供了丰富的扩展点,允许开发者把记忆加载逻辑嵌入 CI、编辑器插件或自定义的聊天界面。命令行界面则定位为开发者友好,类似"cURL for LLMs"的体验,使得在终端内快速调用模型、切换工作区和查看记忆变得轻便。因为设计上不强制绑定某个云服务或模型供应商,团队可以依据隐私、成本和性能的权衡选择合适的模型后端。
当然,任何系统都有局限与挑战。如何确保长期记忆不产生"陈旧偏见"?如何在保证隐私的前提下实现高效的跨设备同步?如何处理工作区间的知识共用与冲突?Llmswap 提供了部分机制来应对这些问题,例如带有信任级别标记的记忆共享、用户审批的跨工作区合并流程,以及基于时间窗口的记忆回顾工具,但在大规模团队协作或极度敏感数据场景下,仍需要企业级治理与策略支持。 从用户采纳的角度来看,最佳实践包括在项目初期就定义记忆写入约定,明确哪些信息应成为长期记忆,哪些只属于短期会话。保持记忆文件可读并纳入版本控制可以让回溯与审计变得自然。定期进行记忆复盘会提高记忆质量并减少积累噪音。对于教育场景,设置明确的学习目标与里程碑能帮助自动学习日记更准确地抽取关键进展。
展望未来,Llmswap 的发展方向可能包括对多模态记忆的支持(将图像、音频与代码片段与文本记忆统一),更精细的权限模型以支持复杂的企业组织结构,以及与更多开发工具链的深度集成,例如在 IDE 内原生呈现工作区记忆、在 CI 流程中自动生成决策文档等。社区驱动的插件生态也能让不同行业的知识工作者快速适配各自的记忆结构与抽取规则。 对关心厂商锁定与成本的团队,Llmswap 的零锁定承诺值得关注。用户可以自由选择或切换模型供应商,同时保有本地可读的记忆文件,这种设计降低了长期迁移的障碍,并为合规性提供主动性控制。对个人用户而言,开源与可离线运行的能力意味着在隐私和可控制性上有更多主动权。 总的来说,Llmswap 把"第二大脑"概念推向了更实用的维度:不是构建一个笼统的、单一的记忆体,而是把记忆与项目、学习路径和生活场景绑定,让 AI 在每次交互中都带有可持续的、上下文相关的记忆。
对于频繁在多个项目之间切换、需要长期积累知识与决策痕迹的开发者和知识工作者,Llmswap 提供了一种实用且可扩展的解决方案。 如果想进一步了解或试用,可以访问其开源仓库以获取代码与安装说明,或通过 Python 包管理器快速上手。社区反馈将有助于完善工作区功能、记忆抽取的精准度以及团队协作的治理机制。对于希望让 AI 不再"短期记忆"而真正成为长期助力的用户,Llmswap 值得一试。 。