在计算机系统研究与工程实践中,基准测试(benchmarking)是一把双刃剑。正确使用时,它能揭示性能瓶颈、检验优化效果并支持科学比较;错误使用时,它则会误导读者、扭曲结论,甚至破坏学术与工程判断。Gernot Heiser 所总结的"基准测试罪行"为社区提供了一份警醒清单,本文以通俗语言梳理这些常见误区并给出可操作的最佳实践,帮助你在性能评估中做到公平、严谨与可复现。文章面向系统研究人员、性能工程师与审稿人,强调如何识别和避免基准测试滥用,提升工作可信度。 许多基准测试问题的核心来自选择性地展示结果。选择性基准(selective benchmarking)指的是只呈现那些支持作者论点的测试案例,而隐藏其它代表性或不利的结果。
更危险的一种变体是基准子集化(subsetting):当使用大型基准套件(如 SPEC)时,仅运行其中一部分并把子集结果当作整体结论,这会严重误导。除非能够合理解释为何排除某些子基准并声明结果的局限性,否则任何总体平均数都应被视为不可信。与此相关的还有选择性数据集(selective data set),即故意在参数范围外避开真实负载所在的关键区域,从而把性能问题掩盖起来。 另一个高发问题是过度依赖微基准(microbenchmarks)。微基准擅长测量某一具体操作的代价,例如系统调用延迟或上下文切换成本,但它们不能反映复杂工作负载的整体表现。用一组微基准来证明系统在实际应用场景中表现优异是危险的逻辑跳跃。
相反,应当结合宏基准(macrobenchmarks)或真实业务工作负载来验证整体性能。少数例外存在,例如当某一操作被广泛认为为系统瓶颈时,显著改善该操作的成本可以有指示性价值,但仍需谨慎解释。 在展示性能代价时,常见错误还包括把吞吐量下降直接等同为"开销百分比"。吞吐量下降受多种因素影响,包括CPU占用、延迟变化、缓存策略以及IO瓶颈等。举例来说,当系统吞吐量下降10%时,如果原先CPU并未饱和,这种下降可能源于延迟增大而非每单位工作量的处理成本增加;相反,如果CPU已经处于完全负载状态,吞吐量下降更可能反映了处理成本的上升。因此在比较吞吐量时,必须同时报告完整CPU利用率或计算"每比特的处理时间"以便合理量化开销。
一些作者也会通过不当选择参考点来淡化开销描述,例如用改进后的系统作为分母来计算性能提升或退化的相对值,从而给出诱人的百分比。正确做法是将明确、合适的基线系统置于分母位置,通常基线应为原始或业内公认的最优方案。此外,关于百分比的表达也必须小心,避免混淆百分比与百分比点的概念,否则会对变化幅度产生严重误导。 统计显著性和不确定性往往被忽视。仅仅给出平均值而不提供方差、置信区间或多次重复试验的结果,使得任何差异都可能只是偶然波动。对重复实验计算并报告标准差或置信区间是最基本的要求;在结果差异很小或方差很大时,应使用合适的统计检验(如t检验)判断差异是否显著。
此外,在收集数据时应设计足够的样本量与独立运行,以避免缓存、热启动或系统状态漂移导致的偏差。 另一个常见错误是用算术平均数来对多项基准结果求综合得分。算术平均在各子项值跨度很大或已归一化时会产生误导。对于比率类指标或相对性能分数,几何平均通常是更合理的汇总方法,因为它能保持乘法可交换性并避免被极端值拉偏。 模拟系统或精简模型的评估需要格外谨慎。模拟往往基于一系列假设,如果这些假设与待评估的性能特征相冲突,结果就会失真。
使用模拟时应明确说明模型假设并验证模型对关键度量的代表性。切不可在校准数据与验证数据上使用相同的工作负载或输入集,否则所得到的结果只是对已知数据的拟合而非对未知情况的预测能力测试。校准与验证必须互相独立,否则模型泛化能力无法得到信任。 在对比不同系统或方案时,基线选择和对手系统的公平处理同样重要。常见的错误包括:缺乏适当基线(例如未提供原生系统的性能作为参考)、仅与自家旧版本比较而忽略行业最新进展,以及在复现对手系统时配置不当导致不公平结果。为避免这些问题,务必清楚列出对手系统的配置、版本与运行参数;若可能,与对手作者沟通确认复现设置;并采用最新公认的基线作为比较目标。
此外,历史上曾出现以旧基线为标准夸大性能提升的情况,要始终把先前文献中的最好结果视为新的比较基准。 报告结果时要尽量完整透明。缺失平台规格、只给出相对数值而不提供绝对数值、或仅展示总体得分而隐藏子项详细结果都会削弱可复现性并降低可信度。评估平台的硬件与软件版本、核心数量、主频、缓存层次结构、网络带宽与交换设备、操作系统版本和编译器等信息都应记录并在文稿中公布。对基准套件的每个子项也应分别展示结果,这能帮助读者理解系统在哪些场景获益或受损。 在展示图表与可视化时应避免"图表滥用"。
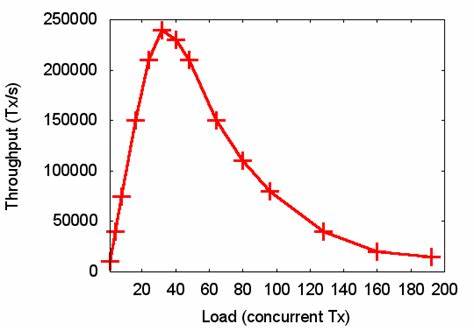
不恰当的坐标缩放、截断Y轴、或故意省略误差条都会放大某些差异、误导读者判断。图表应使用明确标注的刻度、包含误差范围或置信区间,并且在图注中说明测量方法与重复次数。若要突出某段数据,请在文中解释为何该段具有代表性并同时提供完整区间的补充数据。 为了提升基准测试质量,应把良好实践纳入研究和工程流程。将基准测试纳入回归测试体系、在每次变更后自动执行关键测试集合并记录输出,是保证结果稳定与及时发现回归的有效手段。实验设计阶段需要仔细规划数据生成策略,避免重复使用相同输入导致缓存或去重带来的虚假提升。
运行顺序应交替或随机化以减少测量干扰,必要时对异常点进行统计上的离群检测而非随意剔除。 计时方面需要多次迭代、充分的预热以稳定系统状态,剔除循环与函数调用开销的影响,并在可能的情况下检查机器码以确认测时逻辑与预期一致。对于长跑任务,监控系统资源随时间的变化可以帮助识别渐进性问题,如内存泄漏或后台服务干扰。对于并发或多核测量,务必记录核心亲和性设置与调度策略,因为这些细节往往对结果产生巨大影响。 学术与产业界都应当对基准测试伦理保持敏感。故意以不完整或误导性的实验支撑结论是一种学术不端,会损害个人与机构信誉。
审稿人有责任识别上述问题并要求作者补充必要信息或重跑实验。研究团队内部也应建立共同的评估规范和审查流程,鼓励开放数据与开放代码,以便同行复现与验证。 总结来说,可靠的系统基准测试建立在全面、透明与严谨的实验设计之上。避免选择性呈现、恰当使用微基准与宏基准、准确计算并报告开销、进行统计检验、选择合理基线、详细记录平台信息与子项结果,都是提升评估可信度的关键步骤。将这些原则内化到日常研究与工程实践中,能显著提高结论的可信度与长期价值,为学术交流与工程决策提供坚实依据。对于每一位从事系统性能工作的研究者与工程师而言,理解并避免"基准测试罪行"不仅是良好科研伦理的体现,更是实现可持续、可重复与可验证工作的必由之路。
。