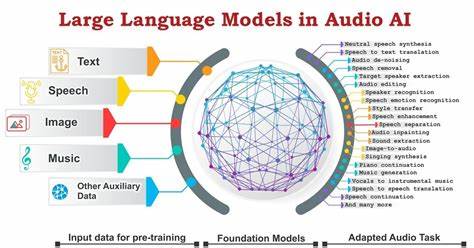
在当今人工智能高速发展的时代,计算能力的瓶颈成为制约创新的重要因素。尤其是在大型语言模型(LLM)的训练和推理中,显存容量与数据传输速度直接影响着模型的表现和效率。为了突破现有硬件的限制,构建一台专用的高性能AI服务器成为许多深度学习爱好者和专业开发者的重要目标。本文将带您了解一位AI爱好者如何在地下室里打造了一台搭载八块RTX 3090显卡、总计192GB显存的终极AI服务器,并分享其中的经验与挑战。 这台AI服务器的灵魂是八块RTX 3090显卡。每块显卡配备24GB显存,总计192GB,能够满足当前主流大型语言模型如Meta的Llama-3.1 405B参数规模运行需求。
显卡之间通过四个NVLink桥梁进行连接,带来了高达112GB/s的数据传输速度,这一速度远超传统PCIe的带宽,有效支持多GPU的张量并行计算架构。 在处理器平台的选择上,采用了Asrock Rack ROMED8-2T主板。这款主板拥有七个PCIe 4.0 x16插槽和128条PCIe通道,提供了充足的带宽支持多显卡协同作业。搭配的是AMD Epyc Milan 7713处理器,拥有64核128线程,基础频率2.0GHz,最高Boost频率达3.675GHz。其强大的多核心性能是保证系统整体计算吞吐的关键。 内存方面,系统选用了512GB DDR4-3200三重通道注册内存,满足了数据预处理和多任务并行运行的需求。
此外,三台1600瓦电源单元保证了系统在满负荷运行时的稳定供电。组装这样一台机箱庞大、性能强劲的AI服务器,不仅考验硬件选型,更是对工程技术的挑战。 作者在组装过程中遇到了诸多困难,从为机箱钻孔固定金属框架,到晕头转向的小插曲如CPU插槽针脚弯曲,均体现出DIY高端硬件组装的复杂性与细节。特别是在多GPU节点中,PCIe扩展连接成为重中之重。传统PCIe延长线存在信号衰减问题,容易导致传输错误。为此,采用SAS设备适配器、Redrivers和Retimers来确保信号完整性,避免因硬件连接不良影响系统性能。
系统软件方面,推理引擎的选择同样重要。主流的如TensorRT-LLM、vLLM及Aphrodite Engine等,不仅支持多GPU张量并行,还针对不同硬件架构进行了优化。通过细致的性能基准测试,作者分析了各推理引擎的优缺点,为后续模型训练和微调提供坚实基础。 同时,关于高性能AI服务器的设计,还有诸多细节值得关注。关键如PCIe通道带宽、NVLink速度以及显存之间的数据传输效率直接决定了模型训练推理的流畅程度。现代Nvidia驱动层面对原生P2P PCIe带宽进行了软件限制,这让多显卡数据共享更加复杂,因此理解并掌握这些底层机制对优化系统性能至关重要。
此次项目体现了硬件性能与软件深度结合的完美实例。从48GB显存容量瓶颈到如今192GB的壮丽升级,更加令人感叹科技迅猛发展。作者回忆起2004年首次拥抱60GB硬盘的喜悦,对比当下同一台机器中显卡所拥有的数百倍存储与计算能力,令人对未来AI发展充满期待。 这个自建AI服务器不仅是技术实力的展示,更深刻体现出持续学习与突破极限的精神。通过硬件的创新应用,结合多GPU张量并行技术,个人工作室也能够实现曾经只有大型数据中心才能完成的任务。这种趋势正在逐渐改变AI技术的生态格局,推动更多人参与AI模型训练与应用开发,释放前所未有的创造潜能。
随着系列后续深入展开,作者将分享更多关于硬件组装经验、系统调优方法和应用案例。未来内容涵盖如何避免组装中的常见坑点、多显卡系统中的故障排查,以及基于该平台完成的训练项目,包括模型微调与定制化应用开发。这些内容无疑对DIY AI服务器爱好者和专业从业者都具有极高的参考价值。 总结来看,构建一台顶级AI服务器不仅需要优质的硬件和科学的系统设计,更需要对硬件与软件深层机制的深入理解。基于多GPU协同运算的AI计算平台,正成为未来人工智能发展的重要支柱。作为个人实践者,敢于探索、勇于创新,将为AI技术进步贡献宝贵力量。
未来20年内,我们或许将见证更多更强大的服务器与算法诞生,掀起又一轮人工智能的浪潮。 。