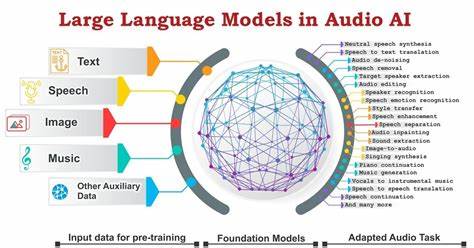
近年来,随着深度学习技术的飞速发展,音频世界模型成为了人工智能领域备受关注的研究热点。所谓音频世界模型,指的是那些能够理解、生成甚至预测现实世界中声音的复杂系统。这些模型不仅能够捕捉声波的频率和振幅信息,还能够识别声音背后的语义内容、情感表达以及环境特征。随着技术的不断演进,音频世界模型的准确性和应用范围正逐步拓展,未来有望在智能助理、娱乐、医疗和安全等多个领域带来深远影响。音频世界模型的核心价值在于它们对声音数据的深层理解。传统的语音识别系统更多依赖于特定的特征提取技术,而现代世界模型通过大规模神经网络结构,能够自动从原始音频数据中学习多维度的特征表示。
这种端到端学习方式不仅提高了模型对语言、口音以及环境噪声的适应能力,也大幅提升了识别的精确度和鲁棒性。随着计算能力的提升,音频世界模型逐渐实现了跨模态的信息融合。通过结合视觉、文本甚至传感器数据,这些模型能够对复杂的多媒体场景做出更为全面的分析。例如,结合视频与音频信息识别环境中人的动作与言语,为智能监控和增强现实应用提供更丰富的交互体验。此外,生成式音频模型的进步同样令人瞩目。借助生成对抗网络(GAN)和变分自编码器(VAE)等技术,模型能够合成高质量、自然流畅的声音。
这在虚拟角色配音、情感语音合成乃至语音转换等领域展现出巨大潜力。此次革新不仅限于声音的表层模拟,更加注重语音的情感语调和个性化表达,使虚拟语音更加贴近真实人声,提升用户体验。音频世界模型的进步也大大推动了语音助手和智能家居设备的发展。通过更细致地理解用户指令的语境和语气,智能设备能够提供更为精准和个性化的响应。未来,随着模型不断完善,语音交互将变得更加自然和无缝,极大地改变人机交互方式,形成更加智能化的生活环境。在医疗领域,音频世界模型也展示出独特优势。
通过分析病人的呼吸声、咳嗽声和语音异常等音频信号,医生能够获得更为客观和及时的诊断依据。这种无创检测方式将大幅提升疾病的早期发现和管理效果,特别是在远程医疗和健康监测中具有重要意义。值得注意的是,音频世界模型的进步也带来了隐私和安全的新挑战。模型对大量个人语音数据的依赖,使得数据保护和使用规范成为必须重视的问题。研究者和企业正积极探索通过联邦学习、差分隐私等技术保障用户数据安全,同时提升模型性能和泛化能力。未来,音频世界模型有望继续结合更多先进算法与硬件优化,实现更高效的数据处理和更广泛的应用布局。
随着5G、边缘计算等技术的普及,实时音频处理的能力将大幅增强,使得智能设备在低延迟环境下响应复杂任务成为可能。此外,跨语言、跨文化音频模型的发展也将促进全球范围的沟通与理解,打破语言障碍,推动多样化信息交流。总而言之,音频世界模型正逐渐成为人工智能领域不可或缺的基石。通过从声音的深层结构中汲取信息,这些模型不仅提升了技术的多样性和智能水平,也为社会各个层面带来了创新机遇。随着研究的不断深入和技术的成熟,未来音频世界模型将在更广泛的场景中实现颠覆性应用,塑造一个更加丰富多彩的声音未来。 。