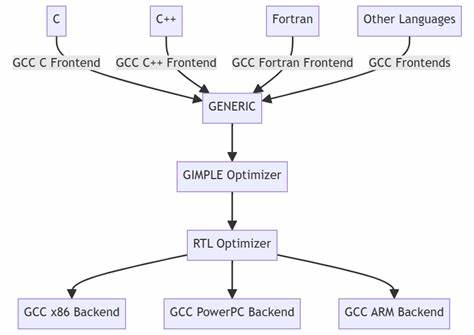
Rust作为一门现代系统编程语言,其编译器rustc长期以来依赖LLVM作为后端代码生成工具。LLVM强大的中间代码优化与丰富的目标平台支持,使其成为Rust编译器不可或缺的组成部分。尽管如此,近年来有开发者尝试以GCC作为Rust编译器的替代代码生成器,目标是构建一个依赖GCC而非LLVM的Rust编译器版本,既能提升编译效率,又能扩大Rust编译器的适用场景。构建Rust编译器本身即是一项复杂的任务,要在保持语义一致性的基础上实现新的代码生成路径,则更是难中之难。本文将详细介绍该项目的启动背景、三阶段引导构建流程、遇到的主要技术挑战,及其背后的深层次原理和解决方法。Rust编译器的引导(Bootstrap)流程设计为三大阶段。
最初,使用基于LLVM的现有Rust编译器构建一个带有GCC代码生成器的编译器版本。接着,利用该GCC代码生成器重新构建Rust编译器自身,以确保其依赖GCC工具链而非LLVM。最后,将第二阶段产出的编译器再构建一次,作为一致性与稳定性的验证。如果第一、二阶段产生的二进制输出完全一致,那么基于GCC的Rust编译器在功能上就达到了与传统LLVM路径相当的水平。这一三阶段策略合理地将引导构建过程划分,有助于逐步排查和解决GCC代码生成中存在的bug和不兼容问题。然而,实践过程中,项目遭遇了诸多棘手的技术难点。
其重要的一环是继承LLVM代码生成的诸多隐式假设,并在GCC生态中重新表达这些机制,尤其挑战巨大。最初表现为libgccjit库产生的中间表示(IR)相关错误,如类型不匹配和非法内联行为。一个典型问题源于Rust代码中的递归函数使用#[inline(always)]属性。该属性在LLVM中被视为建议,并非强制,而GCC代码生成器则严格执行,导致要求无法满足的无限递归内联请求,进而引发构建失败。深入分析发现,LLVM的这一行为其实是一种软性优化:即使标注always inline,也并不保证对所有调用都进行展开,特别是递归场景。而GCC坚持要求所有调用均展开,无法忍受递归循环。
项目组因此针对递归函数的内联策略进行了调整。在新的方案里,所有使用#[inline(always)]的函数默认降级为普通的#[inline],避免无条件内联。虽然这种做法牺牲了部分性能优势,却极大增强了编译器构建的稳定性。同时,为了识别更复杂的间接递归调用场景(即函数A调用函数B,B又调用A),研究人员利用Rust编译器的中间表示MIR结构,对函数调用图进行静态分析,检测是否存在嵌套的inline(always)调用链,从而动态决定是否应用降级内联策略。该方法不仅有效解决了直接递归问题,也覆盖了间接递归情况,保障了GCC代码生成的正确性。除了内联属性问题,128位整型的SwitchInt终结器实现也是重大障碍。
Rust MIR中条件跳转依赖SwitchInt机制,类似于C语言中的switch语句。由于目标切换整数可能具有128位宽度,需要在libgccjit中生成对应的128位常量。然而,现有libgccjit接口只能支持64位参数,缺乏创建128位整型常量的直观API。尝试模拟生成128位常量时,只能通过组合高低64位表达式,导致无法用于case分支判断,引发编译中断。为解决该缺陷,有人提出修改libgccjit引入直接支持128位常量生成的新函数,但由于GCC不同位宽平台支持不一,此举充满挑战。短期内项目采用了更为低效但行之有效的if-else阶梯结构,替代switch实现128位值匹配。
该方案虽显呆板,却依赖GCC的优化能力减少性能损失,保障了功能正确。另一令团队头疼的问题是构建过程中阶段二编译器的崩溃。分析核心转储定位于Rust编译器内部的intern_valtree函数,即类型驻留器的哈希表处理阶段。通过反汇编检查断点期待载入对齐的256位向量数据时,发现地址仅 16 字节对齐,未满足 AVX 指令所需的 32 字节签字段对齐,从而产生非法访问导致段错误。深入源码发现原因与Rust频繁使用的#[repr(packed(1))]属性有关,特别是对包含u128字段的ScalarInt结构体。此属性允许数据压缩但取消了默认对齐保障,导致访问时必须使用非对齐加载指令。
GCC代码生成器未正确识别该场景,错误生成了对齐加载指令。为补救,团队调整了载入类型的对齐处理逻辑,对于u128类型,确保在已针对正确对齐设置情况下避免重复调用调整函数,防止加载指令不匹配。通过该修正,编译器引导得以顺利进入第三阶段,尽管性能表现需进一步提升,内存占用仍过高,且偶有栈溢出现象待解决。整体来看,用GCC替代LLVM构建Rust编译器虽耗费巨大努力,但为Rust生态带来了多重可能。首先,此举降低了Rust对LLVM生态的依赖,意味着随着LLVM演进出现的兼容性问题将不再束缚Rust发展。其次,利用GCC成熟的优化器和跨架构支持,可为Rust拓展具有优势的平台,尤其是嵌入式和低功耗设备。
再者,该项目丰富了Rust编译器的后端设计,为未来多元化代码生成奠定基础。此次改造过程显著揭示了Rust编译器设计的复杂性和深度,包括语言特性对代码生成的隐晦需求与高级优化对产出质量的影响。对GCC libgccjit的扩展与修正,也有望推动GCC生态更加友好地支持新兴编程语言。此外,从调试手段层面来看,该项目遇到的调试困难反映了编译器引导流程本身的复杂性,如对构建环境的依赖、运行时环境复杂性,以及多层代码转换带来的可追踪性问题。未来可期望更多专门工具协助分析及追踪跨阶段编译错误。总而言之,用GCC构建Rust编译器不仅是一场技术攻坚,也是一项对编译器架构持续进化的深刻探索。
该项目通过循序渐进的重大技术突破,逐步攻克核心难题,逐渐实现了从理论走向实用的飞跃。成功构建基于GCC的Rust编译器,不仅有助于Rust社区实现技术多样化,也为系统编程语言生态注入新的活力。期待未来会有更多关于此项工作的分享,包括ABI兼容性调整、ARM平台上的移植细节、整合自动化模糊测试技术及基于GCC的代码生成性能优化等。持续关注该项目,将能见证Rust编译器引导策略的重大革新和生态格局的进一步完善。