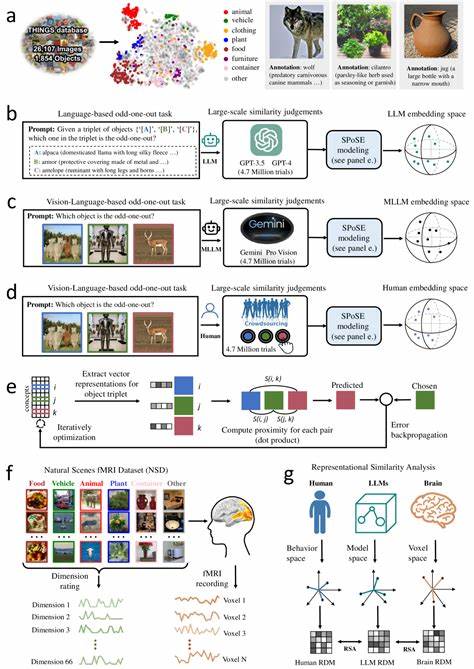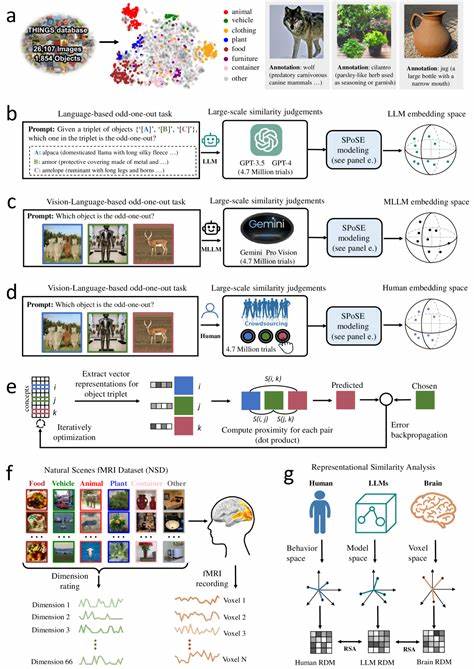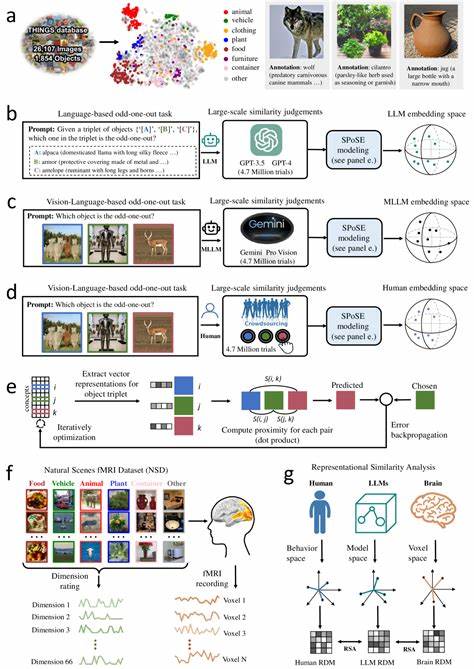
随着人工智能技术的快速发展,大型语言模型(Large Language Models,简称LLMs)逐渐成为研究热点,尤其是在模拟和理解人类认知方面展现出巨大潜力。近年来,多模态大型语言模型(Multimodal Large Language Models,简称MLLMs)通过融合语言和视觉信息,开始展现出类似人类的物体概念表征,为深入理解人类如何感知和分类自然物体提供了崭新的视角。理解人类是如何概念化和分类自然物体,不仅是认知科学的基础问题,更关乎打造具备高级认知能力的人工智能系统。最新的研究结合了行为学实验与神经影像技术,利用大规模数据集对比人类与多模态大型语言模型对自然物体的相似性判断,揭示了令人振奋的发现。该研究收集了来自模型和人类的数百万次物体三元组判断,通过先进的算法从中得出了低维度的嵌入表示,成功捕捉到1854种自然物体的相似结构。最终的66维特征空间不仅稳定且具预测力,更表现出与人类心智表征相似的语义聚类。
更为重要的是,这些维度往往是可解释的,显示MLLMs的物体概念表征具有类似人类的语义组织结构,这意味着机器学习模型在没有明确教授概念范畴的情况下,也能自然地形成具有人类认知意义的概念结构。进一步的神经影像对比分析显示,这些模型嵌入与人类大脑多个特定视觉区域的神经活动高度一致,包括外视觉体区(extrastriate body area)、海马旁回区域(parahippocampal place area)、回顶叶皮层(retrosplenial cortex)以及梭状回面孔区(fusiform face area)。这些脑区均与物体感知、场景识别及面孔处理相关,说明多模态模型内部的表征机制与人类脑内的视觉信息处理路径高度契合。这样的发现不仅支持了多模态模型在模拟人类复杂认知方面的有效性,也为人工智能领域提供了重要理论依据,指明了如何借鉴神经科学知识来改进模型结构与训练方法。多模态大型语言模型通过将文本与图像等多源数据整合,有效实现跨模态的语义融合,使得模型不仅能够理解纯语言信息,还能通过视觉信息建立更丰富的物体概念体系。相比传统仅基于语言的大型模型,这类模型在物体识别与分类任务上表现出更接近人类的判断能力,使其在图像检索、自动描述生成以及智能交互等应用场景中更加高效智能。
值得关注的是,这些模型中学习到的表征维度往往映射着描述对象的基本特征,如颜色、形状、用途甚至情感联想,显示人类对物体的多维度感知在模型中得以显现。此外,对比不同模型的嵌入空间结构可以揭示出它们对物体语义的差异理解,进而指导模型设计者优化训练策略,实现更人性化和精准的认知模拟。除理论与技术层面上的突破,研究还关注了多模态模型与人脑之间的功能对应关系,借助功能性磁共振成像(fMRI)数据建立了模型表征与脑区激活的映射。通过代表性相似性分析方法(Representational Similarity Analysis,RSA),研究表明模型生成的低维语义空间良好地预测了视觉皮层中的神经活动模式,进一步验证了机器学习模型与人类认知系统的结构性相似性。未来,随着数据规模和模型容量持续扩大,多模态大型语言模型在模拟更复杂认知现象、实现更深入的跨模态理解方面将拥有更大的潜力。同时,这也将促进认知神经科学对人类认知过程的反向研究,有助于揭示大脑信息处理的普遍规律。
持续优化模型的解释性能和透明度,将助力建立更可信赖的人机交互系统,推动智能助理、教育辅助、医疗诊断等多领域的创新应用。综上所述,多模态大型语言模型不仅继承了语言模型的强大语义处理能力,更通过融合视觉信息自然形成了类似人类的物体概念表征。这种跨模态的认知框架为理解人类感知、推动人工智能与神经科学的深度融合奠定了坚实基础,开启了智能系统朝向更高层次人类认知模拟的广阔前景。