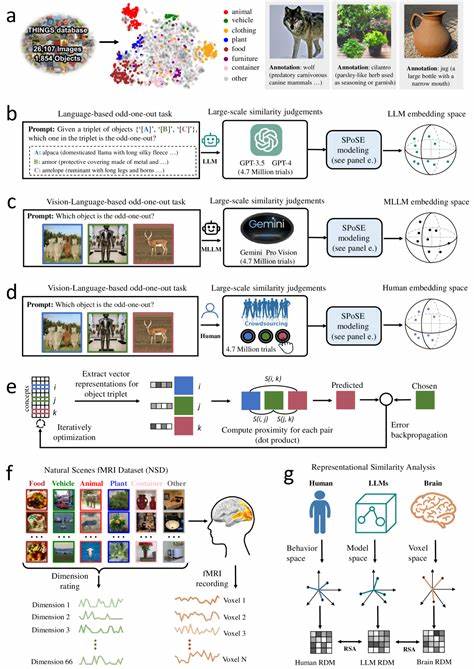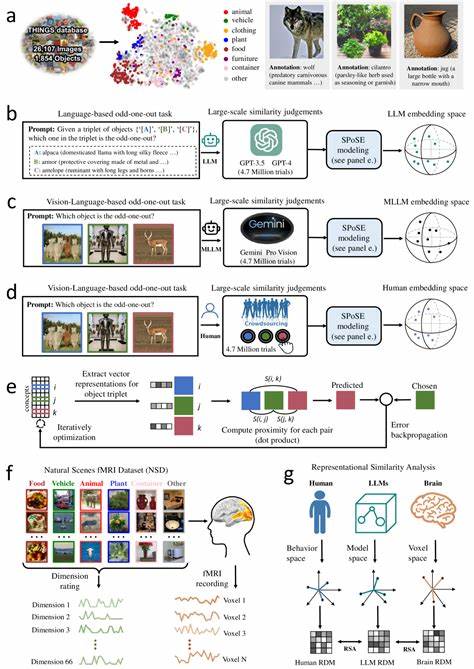
随着人工智能技术的飞速发展,大型语言模型(LLMs)已经成为推动自然语言处理和认知智能研究的关键力量。近年来,结合视觉信息的多模态大型语言模型(Multimodal LLMs)更是展现出超越单一文本处理能力的惊人潜力,尤其在物体概念理解与表征方面,表现出了与人类认知相似的特征。人类如何感知和分类物体,一直是认知神经科学和心理学研究的核心课题。人类的物体概念不仅包含视觉特征,还融合了功能、情境、语义等多维信息,使得人类能够高效识别和理解复杂多样的现实世界。多模态LLMs则通过融合语言与视觉信号,模拟了人类的这种多维感知过程,从而自发形成高度类似人类的物体概念表征。这种发展为探索人工智能与人脑认知的联系提供了独特视角,也为未来智能系统的设计指明新方向。
最新研究基于数百万行为判断数据对多模态LLMs进行了分析,发现这些模型能够通过学习语言描述和视觉信息,构建稳定且低维的物体嵌入空间。该空间中的物体表征不仅具备高度的预测能力,还展现出类似人类认知中的语义聚类特点。例如,关于动物、工具或场所的物体会自然聚集在同一维度,体现了模型对物体类别和属性的敏感度。更重要的是,这些嵌入维度具备良好的可解释性,研究人员能够直观理解某些维度对应的具体语义或视觉属性,类似于认知科学中描述的关键认知维度。这一发现表明,多模态LLMs不仅在表面上模仿人类语言表达,更在深层次的语义组织和感知特征上与人类认知系统产生共鸣。神经成像研究进一步验证了这种观点。
模型中的物体表征与人脑中多个关键区域的神经活动高度契合,诸如体部外侧区、海马旁回、回顾皮层和梭状脸区等脑区在处理物体信息时展现出与模型类似的模式。这种跨尺度的对齐不仅彰显了多模态LLMs在模拟人类认知机制方面的潜力,也为将人工智能技术应用于神经科学研究打开了新的可能性。多模态LLMs形成的人类般物体概念表征,兼顾了感知的多样性与认知的复杂性,极大地提升了模型在实际应用中的适应性。例如,在图像理解、视觉问答、机器人感知以及辅助医疗诊断等领域,这类模型能够更准确地捕捉和利用物体的语义特征,实现更智能的交互与决策。同时,这些研究成果对理解人类认知过程本身亦提供了借鉴。通过分析模型如何从海量多模态数据中抽取有效特征,科学家可以更深入地揭示人脑如何构建物体概念体系,促进认知神经科学和心理学的交叉发展。
然而,尽管多模态LLMs在人类概念表征方面取得了显著进展,仍存在一定局限性。当前模型的物体表征尚未完全复刻人类的感知细节和情境理解,尤其在处理高度抽象或文化依赖的概念时,表现仍有差距。未来的发展需要更多样化、多层次的训练数据,以及更具认知灵活性的模型架构,以更全面地捕捉人类认知的多维度特征。展望未来,结合神经科学发现与先进的机器学习技术,多模态大型语言模型将在打造类人智能和实现人工通用智能的道路上扮演重要角色。通过持续优化模型的视觉与语言融合机制,以及深化对模型内部表征维度的理解,研究者们有望开发出更贴近人类思维、理解和推理能力的智能系统。这不仅将推动人工智能技术的应用边界,还将促进人类对自身认知本质的认知升级。
总体而言,跨越语言与视觉的多模态大型语言模型,正逐步展现出构建人类般物体概念的自然能力。这一进展不仅丰富了人工智能的理论基础,也为现实世界中的智能应用提供了坚实的技术保障。随着研究的深入,多模态LLMs有望成为连接人类认知科学与先进人工智能技术的桥梁,引领智能时代的新篇章。