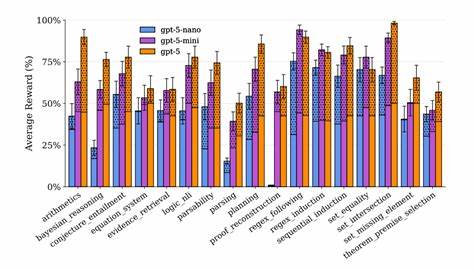
在大数据技术持续高速发展的时代背景下,传统数据仓库和数据湖的瓶颈日益显现,推动了数据湖仓(Data Lakehouse)架构的兴起。到2026年,数据湖仓已从概念走向成熟的运营模式,成为企业构建可信、多引擎访问且具备弹性伸缩能力的数据平台的首选。数据湖仓架构通过在低成本、弹性强的云对象存储之上引入开放表格式、事务性元数据和多引擎访问机制,实现了数据仓库的结构化可信和数据湖的灵活开放的有机融合,为数据工程师和架构师提供了新的思路和工具链。传统数据仓库虽然在数据质量和一致性方面表现优异,但其刚性的模式使得面对JSON、图像、传感器流等多样化数据时显得笨拙和昂贵,且计算与存储绑定导致资源浪费严重。而数据湖则以其Schema-on-read的灵活性和极低的存储成本博得青睐,但缺乏事务性支持、数据治理及性能保障,使得数据质量和信任度难以保障,容易陷入"数据沼泽"。数据湖仓打破这一二元对立,将开放表格式作为关键核心,以文件级别的元数据追踪取代传统目录管理,支持ACID事务、时间旅行和智能剪裁,极大提升了数据可靠性和查询性能。
传统的Hive表通过目录追踪文件,随着数据量和云存储规模的变化,目录扫描成为查询性能瓶颈。现代表格式如Apache Iceberg、Delta Lake、Apache Hudi和Apache Paimon引入了快照和文件清单的概念,元数据结构层级分明,有效管理数十亿文件,实现快速查询规划和高效事务处理。Iceberg作为跨引擎、跨云环境的开放标准,以其隐藏分区和分区演进的能力,在业界广泛被认可,支持Spark、Flink、Trino等多种计算引擎。Delta Lake则以其紧密集成Spark的事务日志和时间旅行特性,在Databricks生态系统中得到了深入应用。Hudi凭借复制写入和合并读取模式,精准支持流式数据摄取和CDC,满足频繁更新的工作负载需求。Paimon专注于流批融合设计,集成Apache Flink,推动实时数据湖仓的实现。
成功的数据湖仓架构分层清晰,底层以云对象存储提供弹性持久且低成本的存储保障,表格式层负责事务和数据演进,摄取层涵盖批量及流式数据引入,目录与治理层确保元数据统一、访问安全和合规追踪,计算与消费层支持多种BI、数据科学及AI用例,形成统一且高效的生态体系。随着AI和数据分析需求急剧攀升,流式计算成为常态,数据摄取从传统的日批变为连续微批,要求精确一次提交并控制小文件数量。同时,AI和代理工作流产生变幻莫测的即席查询,推动底层平台需提供低延迟的自动加速能力。开放互操作亦成为标配,多引擎、多应用访问同一数据源,实现单一可信版本,避免多份数据拷贝和维护冗余。不同的目录和治理方案体现了湖仓灵活的数据管理策略。来自Apache Polaris的开源Iceberg REST目录,注重跨引擎开放标准,支持去锁定的多云多引擎访问;AWS Glue及其Lake Formation提供深度集成的云原生治理,适合AWS用户;微软Fabric OneLake和Google BigLake分别为Azure和GCP生态构建统一目录,实现了湖仓的云端运维与安全机制;项目Nessie引入类似Git的分支和多表原子提交机制,助力开发测试环境。
元数据管理不仅是数据一致性和事务性的保障,也是性能优化的切入口。通过合理的文件压缩与合并、小文件治理、快照过期清理以及分区演进和聚簇等策略,平台能持续控制存储占用和查询响应时长。加速引擎利用列统计、布隆过滤器等技术智能跳过无关数据块,结合Dremio等平台提供的自动刷新物化视图,显著提升复杂查询吞吐量和稳定性。伴随数据湖仓的发展,Python生态快速完善。DuckDB作为内嵌式分析引擎,以零依赖和高效执行成为本地实验和轻量分析首选。Dask通过分布式调度支持大规模Python工作负载。
Daft借助Arrow的内存格式,针对AI和ML优化,兼容多计算后端。Emerging的Bauplan则主打无服务器架构和流水线代码,提高数据开发效率。图数据分析突破传统表格限制,PuppyGraph赋能大规模图查询和遍历,直接联通湖仓,不需额外维护图数据库,支持多种图查询语言与AI增强检索,为金融反欺诈、网络安全、供应链优化等场景提供强力工具。边缘计算结合湖仓也迈出新步伐。Spice AI等平台利用DataFusion和矢量搜索技术,将推理过程前移至数据产生端,满足低延迟、节约成本及隐私合规要求,实现同步回传与全球一致性的平衡。创新的表格式设计如DuckLake,将元数据存储在传统关系数据库中,简化元数据管理流程并提升元数据一致性,特别适合小团队和测试流水线。
目前仍处于快速演进阶段,未来有望成为元数据管理的重要补充。丰富的专业书籍为技术人员提供系统学习路径,涵盖深度解析Iceberg架构、Delta Lake的事务日志与优化策略、Hudi的增量处理与索引、实战湖仓设计及数据平台搭建等,助力行业从业者构筑现代数据基础设施。总结来看,数据湖仓作为现代数据架构的必然演进,融合了数据仓库的信任与治理优势以及数据湖的弹性与开放,已成为推动企业数字化转型和智能化升级的核心支柱。通过采纳开放表格式、构建分层架构、持续优化性能并拥抱AI驱动的数据消费机制,企业能够实现数据价值的最大释放。在迎接2026年的数据挑战时,拥抱数据湖仓便是确保未来数据平台具备灵活性、信任度和高性能的最佳路径。 。