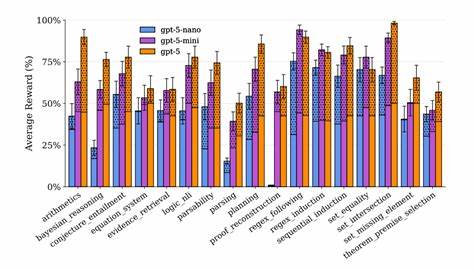
随着人工智能技术的飞速发展,大型语言模型(LLM)在自然语言理解和生成方面展现出巨大的潜力。然而,作为智能系统关键能力之一的符号推理,仍然是当前模型面临的重要挑战。Reasoning Core作为一个创新的强化学习环境,针对大型语言模型的符号推理问题提供了可扩展的解决方案,助力模型实现更复杂的逻辑和数学推理能力。Reasoning Core是一个基于文本的强化学习环境,专为训练和评估大型语言模型的符号推理任务而设计。它支持表达力极强的符号任务,包括一阶逻辑(FOL)、形式数学(如TPTP问题库)、形式规划,以及多种语法相关课题。通过程序化生成多样化的数据,Reasoning Core不仅提高了训练的效率,还增强了模型泛化能力。
传统符号推理任务通常因其高度结构化和复杂逻辑关系,对数据和计算资源要求极高。Reasoning Core巧妙结合强化学习与符号系统,利用可调节的任务生成机制,支持多维度的符号推理探索,使得模型能够在受控环境中不断优化策略,提升推理准确度和效率。此外,Reasoning Core通过丰富的任务配置和灵活的接口,满足不同规模和需求的研究者和开发者的使用场景。人们可以通过简单的代码调用,生成各种符号推理样例,进行系统性的模型评估,同时也能整合到已有的推理训练框架中,发挥协同优势。Reasoning Core不仅仅是一个训练平台,更是一个推动符号推理研究方向的开源社区资源。它开创性地融合了强化学习领域最前沿的技术,融合了对传统逻辑学及形式数学的深刻理解,为人工智能的智能推理划出一条明确的路径。
基于Reasoning Core,研究人员可以针对具体的逻辑系统设计更加细粒度的教学任务,使大型语言模型具备从基础数学计算到复杂定理证明的多层次推理能力。通过反复试验和调优,模型能够在多样数据上表现出优异的推理质量,这对于学术科研和工业应用均具有积极意义。此外,Reasoning Core的可扩展架构支持多线程数据生成及分布式训练,可满足大规模训练需求,保证了其作为行业级框架的稳定性和效率。环境与流行的推理竞赛数据集及任务配合紧密,极大简化了模型评估工作,推动了社区研究的标准化和透明度。从应用角度看,强化学习辅以符号推理的能力,能显著增强大型语言模型在自然语言推理、自动定理证明、复杂语义分析及智能规划等领域的表现。例如,在自然语言推理中,模型不仅仅停留在表层信息的理解,而是能够深入挖掘语义之间的逻辑联系,在复杂情景下给出准确且合理的判断。
在自动定理证明领域,Reasoning Core为模型提供了丰富的训练样例,使其能够逐步掌握形式数学里面的结构化推理方法,推动机器证明技术的进步。技术层面,Reasoning Core采用了一套包含环境加载、任务生成、答案评分和数据集构建的完整工具链,支持Python调用和集成。其设计理念强调模块化和接口统一,方便用户灵活使用,同时保持系统的高性能和稳定性。结合开源社区的力量,Reasoning Core不断更新和优化,吸引了众多AI研究人员和开发者参与协作,形成了良好的生态环境。未来,随着大型语言模型对复杂认知任务的需求增长,Reasoning Core有望进一步扩展到更多符号系统和推理机制,涵盖模糊逻辑、多模态推理等新兴领域。同时,增强与强化学习技术的深度融合,将使得模型在自监督及少样本环境下获得更强的推理能力。
总而言之,Reasoning Core作为面向大型语言模型的符号推理强化学习环境,结合了理论与实践优势,为AI智能推理注入了强大动力。通过提供丰富、多样且可控的任务环境,它帮助模型适应真实世界中复杂且严格的推理需求,推动了人工智能迈向真正理解和解决问题的新时代。其开创性的设计理念和广泛的适用性,必将在未来的智能推理研究和应用中发挥深远影响,成为推动智能系统迈向人类认知高度的重要基石。 。