随着人工智能和高性能计算需求日益增长,GPU架构的进步成为推动计算力革命的核心动力。AMD在2025年6月隆重发布了全新CDNA 4架构,这是其继CDNA 3之后的最新计算型GPU技术,专为满足机器学习和高性能计算挑战而设计。本文将深入探讨CDNA 4架构的技术革新、系统架构和整体性能表现,解析其如何在激烈的市场竞争中保持优势,并推动未来计算能力的提升。 CDNA 4作为AMD计算加速器的新旗舰,继承了CDNA 3的系统架构设计,采用了独特的芯片组合策略。其核心构成由加速计算芯片(XCD)组成,每个XCD内部包含大量计算单元(Compute Units,简称CU),类似于AMD CPU产品中的核心复合体芯片(CCD)。整片GPU通过四个基底芯片承载,配合256MB的侧缓存(memory side cache)以及AMD的Infinity Fabric,构建起一次高度统一且相互连通的内存访问平台。
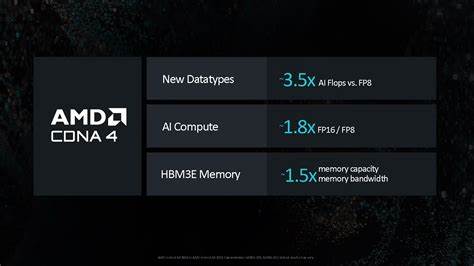
这种架构设计不仅提升了缓存一致性,更显著增强了多芯片协同处理的能力,是AMD继承并发扬其多核CPU设计哲学的显著体现。 相较于上一代基于CDNA 3的MI300X,搭载CDNA 4的MI355X在计算单元数量方面有所调整,每个XCD的CU数量略有减少,同时为了提升良率关闭了更多计算单元。虽然算力单元数量有所缩水,但CDNA 4通过提升核心时钟频率以及大幅优化矩阵乘法性能,整体性能表现依旧强劲。特别是在机器学习任务中,低精度矩阵乘法能力得到了显著增强,单个计算单元的矩阵乘法吞吐量实现了翻倍提升。在FP6这类极低精度数据类型优势尤为明显,使得AMD在AI训练和推理中的效率得到实质性提升。 机器学习工作负载对低精度矩阵计算的需求极大,而NVIDIA的B200 GPU在此领域仍保持强劲的竞争力,尤其是在16位和8位数据类型处理上,其每个流处理器单元(SM)拥有两倍于CDNA 4计算单元的单周期矩阵乘法吞吐率。
AMD则以更大规模、更高时钟频率的GPU整体实力来弥补单元效率不足,确保在总吞吐量上保持领先地位。 在对高精度和矢量计算的支持方面,CDNA 4延续了其上一代MI300X的巨大优势。每个计算单元拥有128条FP32流水线,每个周期能够提供256次浮点运算(Fused Multiply-Add,FMA)能力,在高性能科学计算和传统图形处理任务中表现尤为出色。尽管MI355X的计算单元数量相对较少,整体矢量性能仍保持行业领先地位。在对比NVIDIA新一代Blackwell架构时,AMD凭借更高的核心数量和更快的时钟,维持了明显的矢量计算吞吐量优势,使其在广泛的高性能计算领域具备极强竞争力。 在本地数据存储方面,CDNA 4同样实现了显著升级。
AMD的局部数据共享区(Local Data Share,LDS)容量从之前的64KB提升至160KB,读取带宽也翻倍达到256字节每时钟。这种设计极大缓解了程序内核的数据访问瓶颈,使得多线程工作组能够更高效地共享和处理数据。例如,单个使用16KB LDS的内核,在CDNA 3架构下能够同时支持4个工作组,而在CDNA 4架构下则支持提高至10个工作组,显著提升了线程并行度和性能利用率。 CDNA 4还引入了全新的带转置功能的LDS读取指令,这一指令适用于矩阵乘法中常见的行列转换问题,极大简化了数据访问模式并提升了计算效率。传统上,由于矩阵数据按照行优先或列优先存储,直接进行矩阵乘法时经常导致访问不连续,极大影响执行速度。通过在LDS内部支持转置操作,AMD有效解决了这一问题,进一步提升了机器学习和科学计算的整体吞吐性能。
尽管在局部存储容量上有大幅提升,AMD的CDNA 4每个计算单元的L1缓存仍维持在32KB,相比之下NVIDIA Blackwell的每个SM拥有256KB的共享内存及L1缓存,灵活分配上远超AMD单元。然而,凭借更庞大的计算单元数量,整个GPU的总LDS容量达到40MB,明显高于NVIDIA B200的约33MB,总体存储能力依然可与竞争对手相抗衡。 系统级缓存方面,MI355X也进行了优化。L2缓存不仅提升了写回时的灵活度,还能在清除脏数据(dirty data)时保留数据副本,进而更好地平衡写内存压力。这种进阶式缓存管理可能是在低内存负载时,有效利用写带宽,降低缓存写回带来的延迟和性能波动,从而稳定计算任务的运行效率。 MI355X采用了最新的HBM3E显存技术,极大提升了内存带宽与容量。
其总容量高达288GB,峰值内存带宽8TB/s,从而确保了大规模数据集传输的高效顺畅。这一设计延续了AMD对“大显存”优势的坚持,令其在比对手NVIDIA的B200(180GB容量,7.7TB/s带宽)时占据明显优势。在很多需要超大显存的AI和科学模拟应用中,MI355X能够持续提供更高的数据吞吐和负载支持,保持AMD在显存容量上的领先地位。 计算到带宽比上,MI355X的DRAM带宽相较MI300X有明显提升,从每个FP32浮点操作0.03字节提升至0.05字节,提升了带宽利用效率。尽管NVIDIA Blackwell的带宽效率更高,但AMD明显依赖更大缓存容量来弥补带宽压力,而NVIDIA则更多侧重于依赖动态带宽调度和高速缓存结构。这种带宽与缓存设计理念的差异,反映了两家公司在GPU架构策略上的本质区别,也决定了它们各自在不同应用场景下的优势与劣势。
整体来看,CDNA 4在架构创新上较CDNA 3表现为更为稳健的迭代升级。AMD保持其成功的芯片组合策略,采用少量更高频率的计算单元设计,进一步提升芯片利用率和计算效率。尤其是在矩阵运算性能上的显著提升,让AMD更具竞争力地应对NVIDIA在机器学习领域的挑战。 AMD的这种策略与NVIDIA近几代GPU设计思路有相似之处,后者也主要对于矩阵计算单元进行重点优化,而维持相对稳定的矢量运算单元设计。两家巨头都依靠逐步优化而非大规模重新设计来增强产品竞争力。AMDCDNA 3及其衍生产品不仅推动了高性能计算的发展,甚至还助力了全球超级计算机性能的跃迁,其衍生的MI300A GPU被世界领先超级计算机广泛采用,成为TOP500排序的佼佼者。
展望未来,AMD CDNA 4的发布不仅巩固了其在数据中心及AI计算市场的地位,也为后续融合CDNA与RDNA设计的新品奠定了坚实技术基础。随着AI训练规模和系统复杂度的持续增长,对于更高效、更灵活的GPU架构需求也将愈发迫切。AMD通过持续的技术积累与创新,正在稳步构建应对未来计算挑战的硬件生态系统。 总结而言,CDNA 4是AMD在提升低精度矩阵运算以及扩大本地数据共享能力上的关键突破,配合成熟的芯片组合架构与先进的HBM3E显存技术,使其在机器学习和高性能计算领域实现了综合性能的提升。面对NVIDIA的科技压力,AMD选择在稳定成功的基础上进行细节优化与调整,这种稳健发展路径预计将为其带来可观的市场竞争优势,并推动下一代计算架构的演进。 从技术细节到系统整体,CDNA 4展示了AMD对高性能计算需求的深刻理解和精准应对,在机器学习矩阵性能、矢量计算效率、本地数据管理与系统缓存管理等多维度实现突破。
不仅为今日的计算任务带来性能飞跃,也为未来计算科学和人工智能的发展打下坚实基础。随着市场对计算力需求的爆发,AMD与其CDNA系列架构的持续创新将成为行业关键驱动力之一,值得业界密切关注和期待。