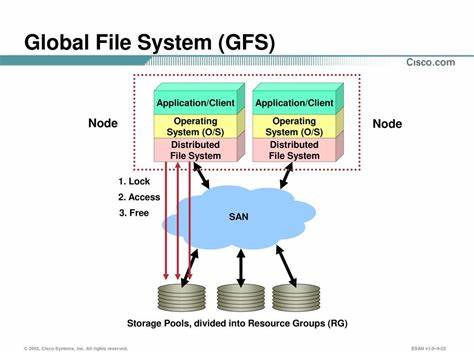
随着数据规模的爆炸性增长,传统的存储和访问模式逐渐显现出瓶颈。无论是人工智能训练、文档索引,还是复杂的数据分析任务,都迫切需要一种既能高效存储超大数据量,又能方便访问和管理的新型解决方案。TigrisFS应运而生,它在全球范围内为用户提供一个方便快捷的文件系统接口,实现了云端数据与本地机器的完美融合。TigrisFS不仅突破了数据存储的容量限制,更革新了数据处理的方式,让大数据变得触手可及。TigrisFS本质上是一个基于FUSE(Filesystem in Userspace)技术的高性能文件系统适配器,它借鉴并延伸了geesefs项目,能够将对象存储桶直接挂载到用户的本地目录中。通过这一方式,用户在本地就能像操作传统硬盘一样访问云端存储的数据,无需担心底层的复杂细节或API调用。
相比传统的对象存储访问模式,TigrisFS最大的优势在于其对POSIX语义的支持,包括权限管理、符号链接和特殊文件的处理,使得在本地操作文件时始终保持一致的用户体验。更值得一提的是,TigrisFS实现了S3 API与文件系统API的无缝互通,用户可以通过S3接口上传文件,也可以用熟悉的编辑器直接修改挂载目录中的内容,极大简化了数据管理流程。这一独特特性打破了其他依赖块级存储且文件名难以识别工具的局限性,使文件访问更直观,更便捷。TigrisFS的设计充分考虑了大数据时代的存储挑战。面对大于单机内存、单个磁盘和单台服务器总容量的数据,TigrisFS通过全球文件系统的理念,将相同数据集挂载在集群中每台机器的相同位置,实现数据共享的即时性。无论在哪一台机器上对数据做出的修改,都能瞬间反映到集群的其他成员,形成高度一致的数据访问环境。
除此之外,TigrisFS还采用智能预取和缓存机制,后台会主动批量获取并缓存小文件,减少访问延迟,提高文件读取速度。小文件处理的优化尤为重要,因为很多分析任务依赖于数以万计的碎片化数据文件,传统文件系统在此场景下往往性能不佳。安全性和稳定性同样是TigrisFS的重要保障。在基础代码层面,它摒弃了带有安全漏洞的老旧AWS SDK,升级了所有依赖库,彻底消除竞态条件,确保代码质量可靠。测试覆盖率的严格扩展与持续集成体系的完善,使得产品在生产环境中的表现稳定,用户体验提升明显。在性能表现方面,TigrisFS展示出惊人的读取和写入吞吐量。
根据官方测试报告,使用专用的I/O测试工具fio,在高性能虚拟机环境中,TigrisFS实现了每秒数千兆字节级的读写速度,完全满足了现代大数据处理对带宽和响应时间的苛刻需求。特别是多线程并发场景下,其性能表现远超很多传统的网络文件系统。这意味着无论是视频转码、机器学习模型训练,还是分布式日志分析,都能高效且流畅地完成数据访问任务。应用层面,TigrisFS的生态兼容性极强。它既支持基于传统文件系统接口的老旧工具如rsync、inotifywait的无缝集成,也兼容新兴的云原生数据消费模式。用户可以将TigrisFS当作一个巨大的共享存储池,将每天生成、变更的数据即时同步到整个集群中,极大提升跨节点合作的效率。
比如在AI训练中,可以直接从挂载路径读取海量训练样本,无需繁琐的数据预处理和同步步骤,节省大量时间和资源。相比需自行搭建复杂分布式存储(如Ceph)环境,TigrisFS提供了更简洁、开箱即用的体验,极大降低了维护门槛。此外,对开发者和运维人员来说,TigrisFS的易用性也是一大亮点。安装过程简单快捷,支持通过一条命令即可完成部署,同时兼容主流Linux发行版的包管理器。配置方面只需提供存储桶名称和访问密钥即可实现挂载,进一步简化上手难度。大量细节优化使得系统运行更稳定,配置灵活性满足不同业务需求。
从未来趋势来看,随着数据量的持续激增和分布式计算的广泛应用,像TigrisFS这样的全球统一文件系统将扮演越来越重要的角色。它不仅解决了传统存储系统在性能与扩展性上的痛点,更为云端数据治理、协同分析和实时应用提供理想基础。尤其在混合云与多云环境中,全局一致的文件视图能够显著降低数据孤岛现象,促进数据价值最大化。总结来看,TigrisFS是现代分布式存储技术的典范。它以开源精神为依托,桥接了云对象存储与本地文件操作间的鸿沟,赋予用户前所未有的数据管理便捷性和高性能体验。无论是科研、工业还是互联网行业,TigrisFS都有潜力成为处理海量异构数据的核心资产。
随着产品迭代和社区壮大,未来TigrisFS有望推出更多智能功能,支持更丰富的数据类型和应用场景,继续引领全球文件系统的创新潮流。对于追求极致效率、灵活扩展和便捷运维的专业用户来说,了解并掌握TigrisFS的使用无疑是提升数据战略竞争力的重要一步。