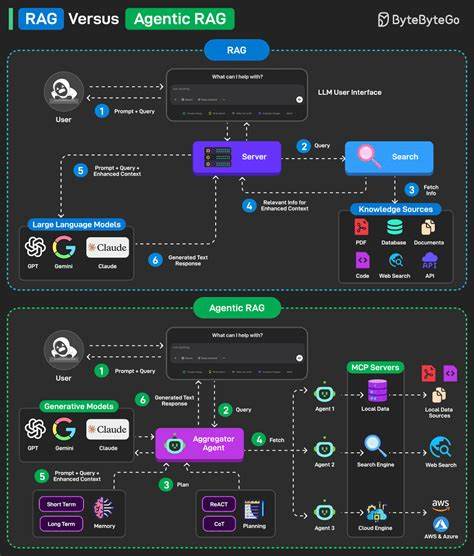
随着人工智能技术的迅速发展,基于大规模参数的语言模型如Mistralai-7B在自然语言处理领域的重要性日益凸显。然而,训练这类庞大模型不仅对硬件资源提出了极高的要求,还对训练框架的效率和分布式能力带来严峻挑战。DeepSpeed作为微软开源的高效分布式训练库,为处理超大规模模型的训练提供了强有力的支持。本文将围绕Mistralai-7B在DeepSpeed流水线架构下的分布式训练展开深入探讨,系统剖析其技术特点、实施方案和实际效果,助力更多开发者和研究者借助现代深度学习技术实现模型训练的突破。Mistralai-7B模型基于先进的Transformer架构设计,拥有70亿参数规模,在保持强大语言理解与生成能力的同时,也带来了训练资源消耗和优化难题。传统单机单卡训练难以满足其庞大参数计算需求,因此采用分布式训练成为必然选择。
通过将模型和数据切分到多台多卡环境,同时兼顾计算负载均衡和内存管理,能够显著提升训练效率和规模。DeepSpeed流水线并行技术在此背景下发挥关键作用。流水线并行的设计思想是将深度神经网络的各层划分为多个子模块,分别分配到不同GPU进行计算。数据在各GPU间以流水线方式传递,实现各子模块的并行执行,有效减少GPU空闲时间,提升算力利用率。相比传统数据并行,流水线并行更适合超大模型,能显著降低通信延迟和内存瓶颈。该方法结合了模型并行和数据并行的优势,形成高度灵活且高效的训练方案。
在具体的Mistralai-7B训练流程中,利用PySpark进行大规模数据预处理,确保训练数据高质量且高并发读取。PySpark具备出色的分布式数据处理能力,能快速从海量原始数据中抽取样本、清洗文字和构造训练样本,充分发挥分布式计算优势,为后续模型训练提供坚实基础。数据创建过程中计算文本间的余弦相似度,对上下文、问题和答案进行关联增强,提升训练数据的语义一致性和模型表现。对于模型训练,DeepSpeed通过融合混合精度计算、梯度累积和零冗余优化(ZeRO)技术,有效管理显存资源,从而支持更多参数的同时保证训练速度。流水线并行具体分阶段执行,数据批次经过各个模型层级的GPU依次处理,实现训练过程中的流水线流畅衔接。结合Mistralai-7B的具体层结构和异构计算平台设计,能够将模型参数和激活态有效切分,避免单个GPU资源瓶颈。
值得注意的是,Java环境配置在PySpark数据处理环节起到了基础性作用。正确安装和配置OpenJDK 17确保分布式数据加载的稳定性,避免因环境不匹配导致的文件读取异常,保证整体训练流程的流畅执行。通过合理规划JAVA_HOME环境变量和系统PATH路径,可以提升集群作业的可移植性与重复性。本文涉及的数据集主要来自NVIDIA Nemotron后训练数据集,结合Mistral-7B指令微调版本,该数据集集成了多样化场景的训练示例,经过精心标注和预处理,适合进行强化学习微调(RLHF),进一步提升模型上下文推理能力和回答准确度。深度集成该数据集与Mistralai-7B模型,有效弥合了通用语言生成与特定任务间的差距。训练环境依赖方面,除了PySpark和DeepSpeed框架外,还有自定义的Python脚本对数据加载、模型构建、训练迭代及指标统计进行细致分工。
项目采用Docker容器打包部署,通过固定的依赖版本和环境变量,保障跨平台复现性。配置文件ds_config.json集中管理DeepSpeed流水线参数,包括分布式通信组设置、显存分配策略以及训练过程日志,方便调试与优化。通过版本管理和持续更新,项目逐步集成更先进的算法组件,修复潜在错误,并优化训练环境配置,提升整体稳定性和性能表现。该开源项目遵循CC BY-NC-ND开源协议,项目代码和权利声明均清晰透明。结合来自Huggingface社区的模型权重及相关数据集,展现了社区协同创新的强大威力。训练结果表明,利用DeepSpeed流水线的分布式训练方案,不仅缩短了训练时间,还显著降低了单卡资源压力,保证了模型在多个GPU节点中的一致性和稳定性。
针对未来发展方向,团队正在探索跨模态层面扩展,将视觉适配器融合进Mistralai-7B,力求赋予模型更强的多模态感知与推理能力。此外,完善训练数据表达方式、引入更智能的采样策略与自监督技术,也是提升模型泛化能力的重要举措。在大规模模型训练日益成为主流的当下,Mistralai-7B分布式训练范例为业界提供了宝贵经验。通过合理利用DeepSpeed流水线的技术优势,结合分布式数据处理与细致的流程管理,使得培养更智能、更高效的语言模型成为可能。未来,随着硬件水平提升和算法优化不断深入,分布式学习技术必将迎来更广泛的应用,为自然语言处理和人工智能领域带来深远变革。