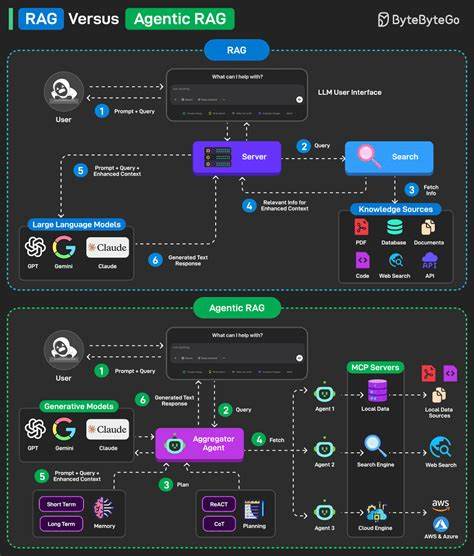
近年来,随着大型语言模型(LLM)和自然语言处理技术的不断突破,检索增强生成(Retrieval-Augmented Generation,简称RAG)成为了人工智能领域一个炙手可热的话题。RAG通过结合预训练语言模型与信息检索技术,旨在提升模型回答问题的准确性与上下文理解能力,看似为解决传统生成模型的局限性提供了新思路。然而,专业人士和开发者间针对RAG是否已经完全成熟、能够稳定应用于生产环境的争议却日益增加。部分声音质疑RAG不过是刚刚从演示项目迈入初步实验阶段,离工业级应用还有一段距离。本文将基于实际案例和专业讨论,解析RAG当前存在的问题,探讨其真实应用状态,并展望未来的发展路径。首先,理解RAG的核心概念至关重要。
传统的生成式模型往往依赖于预训练的大规模语料库,因而在面对特定领域知识或最新信息时,可能出现信息不足或错误生成的情况。RAG试图通过在生成回答之前,先通过检索模块从外部知识库中筛选相关信息,将这些信息作为上下文输入给语言模型,借此增强生成结果的准确性和相关性。这种将检索与生成融合的方式,在理论上是一种以知识为基础的增强策略,能够提升模型对复杂问题的理解和回答能力。然而,实际应用中,许多研发团队发现RAG系统并非“开箱即用”,其稳定性和效果远未达到理想状态。多数情况下,搭建一套高效的RAG解决方案还是依赖于大量的人工干预和不断调试。具体表现为检索模块返回的内容质量参差不齐,可能包含大量无关或者片段信息,这些信息混杂于生成模型的上下文中,导致回答出现语义混乱甚至虚假信息。
更令人头疼的是,用户的多样化提问和跟进问题往往令系统难以应对。一旦遇到复杂或非常规的查询路径,系统的逻辑流和检索机制便可能失效,引发错误传播,产生不符合用户期望的结果。与传统的静态问答系统不同,RAG要求在检索和生成间建立良好的协同关系,尤其在处理用户意图解析和长链推理时,需要设计更为精巧的逻辑路由机制。行业内部部分领先团队尝试通过多阶段提示工程和语义路由技术,搭建类似分支决策树的复杂流程,逐步引导模型生成更合理的回答。这种方法虽然在一定程度上提升了系统性能,但也暴露了RAG方案在设计复杂度和维护成本上的巨大挑战。不仅如此,评价RAG系统的效果也面临难题。
传统评价多依据“检索的上下文是否正确”作为衡量标准,然而这并不等同于“生成答案是否正确”。这种评估差异导致研发人员难以准确判断系统究竟哪里失灵,以及如何针对性地改进 Retriever 与 Generator 之间的接口与流程。部分实践者开始意识到,单纯依赖检索结果作为信息来源并非万能钥匙,反而需要在检索之前引入一层“逻辑判断”或“语义路由”,先分析用户的真实意图,再决定采用哪条检索策略或提示链条,这样才能最大限度地提升回答的相关性和准确性。尽管面临诸多瓶颈,仍有企业级应用取得不错的成绩。例如某些产品团队利用图数据库与知识图谱结合,打造专门针对审计日志和事件追踪的RAG系统,经过大量测试后实现了高达99%以上的准确率。其成功经验主要归功于整体架构的严密设计,以及对业务场景深刻的理解和针对性优化。
这提示我们,RAG技术虽然还未完全成熟,但在特定垂直领域,通过量身定制的策略和精细的系统耦合,依然能够发挥良好效果。归根结底,RAG的应用现状反映了人工智能技术推广过程中普遍存在的“从实验室到生产”的鸿沟。理想与现实之间尚需弥合多方面差距:面向终端用户的稳定性和体验、系统可维护性与扩展性、评测标准的合理设计以及对多样化需求的应变能力。未来的RAG发展方向,或许将聚焦于智能路由机制的构建,提升语义理解与检索的契合度,同时通过增强模型自身的事实核验能力来降低幻觉现象。此外,提升索引和检索管道的鲁棒性,打造一体化、模块化且易于维护的RAG框架,也是淘汰“拼接式”粗制滥造系统的重要突破口。总的来说,尽管检索增强生成技术目前仍处在风口浪尖,其生态环境复杂多变,真正的工业级成熟度尚待时日,RAG展现出的应用潜力和探索价值是不容忽视的。
对于从业人员来说,既要避免盲目乐观,也不能因质疑而阻碍创新探索。理解RAG的局限,结合实际业务需求创新设计,持续迭代优化,才能让这项技术从试验品走向真正的生产利器。在这个过程中,社区交流与经验分享显得尤为重要,只有在实践中互相借鉴,才能共同推进RAG技术迈向更高水准。未来,随着技术的逐步成熟和算法的不断进步,我们有理由相信RAG将成为连接人类知识与智能生成的桥梁,帮助我们更好地应对信息爆炸时代的复杂挑战。