在云原生时代,容器编排成为现代应用部署的基础技能。然而主流编排平台往往功能强大但复杂,初学者难以从源头理解其工作原理。Dubernetes 的诞生正是为了解构这种复杂性,用最小的设计和工程实践,提供一个可运行、可观察、可扩展的"傻瓜"编排器,从而帮助读者通过实践掌握容器编排的核心理念。 为何要构建极简编排器 容器编排的核心在于把"期望状态"映射为"真实状态",并不断进行调和。在 Kubernetes 背后有一套复杂的控制环与控制面组件,但本质上并不需要所有企业级功能来演示这一机制。构建一个极简的编排器可以帮助开发者逐步理解资源声明、API 层、持久化存储、调和循环、容器运行以及流量入口这些关键概念。
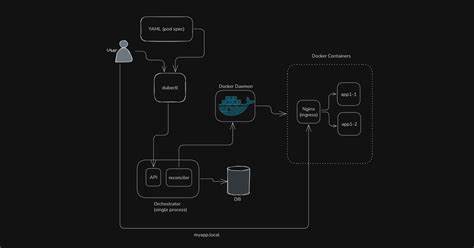
Dubernetes 的目标不是替代成熟平台,而是作为学习工具和实验平台,快速验证想法并快速部署本地服务。 设计原则与技术选型 Dubernetes 以极简为设计宗旨,追求可读性和可测试性。选用 Go 作为实现语言既因为其在云原生生态的广泛使用,也因为 Go 在并发与系统编程上的天然优势。系统只包含最必要的组件:一个单体的 Orchestrator 二进制作为控制面,使用 SQLite 做为轻量级持久化存储,借助系统的 docker 命令或 Docker API 管理容器实例,同时内置一个 nginx 容器作为简单的 ingress,实现域名路由。命令行工具 dubectl 提供用户与 Orchestrator 的交互入口,允许用户通过 YAML 声明期望的 Pod 规格并提交到编排器。 从需求到实现的思路 在动手编码之前,明确好需求非常重要。
Dubernetes 的需求极为简单:用户通过 YAML 声明应用名称、镜像、副本数与访问域名;编排器将这些声明保存为"期望状态";后台有一个调和器周期性查看期望状态与真实运行的容器,执行创建、重启、删除等操作直至二者一致;同时更新 nginx 配置以将外部请求路由到后端容器。为了保证变更安全且可回滚,整个过程依照测试驱动开发的思路推进,每个功能先写测试再实现,确保每次改动不会破坏已有行为。 核心组件解析 Dubernetes 的实现可以分为若干核心模块,各模块职责清晰。API 层负责接收来自 dubectl 的 HTTP 请求,做初步校验并转换为内部的资源请求;数据库模块负责将 Pod、Replica 等元数据写入 SQLite,作为期望状态的持久化;调和器(Reconciler)是系统的心脏,它以循环方式读取数据库中的期望状态,与 docker 上实际容器状态比较,做出创建或删除容器的操作;Docker 管理模块对外包装底层的容器运行细节,包括分配端口、运行容器、设置标签以便识别归属;最后是内置的 nginx ingress,它负责读取当前的路由规则并重新生成配置,从而把外部请求转发到对应的容器实例。 YAML 声明与 dubectl 流程 用户体验上,Dubernetes 提供一个极其简单的 YAML 语法,只需声明应用名称、镜像、期待副本数和访问域名即可。通过 dubectl apply 命令,客户端将 YAML 转换为 API 请求并发送到 Orchestrator。
API 做基础校验后,将请求转换为数据库记录,标记期望状态为运行。随后调和器在下一次循环中发现新的期望状态并创建对应数量的容器。设计上,保持命令接口与 Kubernetes 类似有助于降低学习门槛,但刻意舍弃了复杂概念如 sidecar、init container、多级资源等,以避免概念膨胀。 Reconciler 的职责与实现细节 调和器需要解决的核心问题是如何在故障和变更中保持系统最终一致性。Dubernetes 的 Reconciler 在每次循环中读取所有 Pod 的期望状态与已有的 Replica 记录,然后与 docker 上真实的容器列表进行比对。若发现某个副本失败或丢失,则根据策略重建;若发现实际运行的副本数超过期望,则优雅地删除多余副本;若副本少于期望,则创建新的容器。
创建容器时需要做端口分配、防止端口冲突、生成唯一的副本 ID,并先在数据库记录副本信息以便一致性观察,再调用 docker 运行容器,最后更新数据库中的实际运行状态。对于失败检测,Dubernetes 采用简单的健康判断与容器退出码来判断是否需要重启,而非复杂的探针机制。 内置 ingress 的实现与使用体验 为了实现外部访问的方便性,Dubernetes 内置了一个 nginx 容器作为 ingress。每当调和器改变路由信息时,会从数据库中读取需要暴露的域名与对应的后端地址集合,渲染 nginx 配置并触发 nginx 重载。这样用户可以通过修改 YAML 中的 host 字段,快速将域名映射到对应的服务上。调试时可以使用 curl 的 --resolve 参数把域名指向本地地址,从而模拟真实 DNS 条件。
虽然这套机制不具备 Kubernetes Ingress 等高级路由功能,但对于本地开发与学习场景已经足够。 Test Driven Development 与会话连续性实践 作者在项目开发中采用了测试驱动开发的策略,用单元测试和集成测试来保证每一步实现的正确性。此外,借助 Claude Code 作为协助工具进行"vibe coding",通过明确的项目状态文件来保持会话连续性与上下文一致,从而避免模型在长会话中出现性能下降或偏离设计目标的情况。每完成一个里程碑就重置上下文,确保下一阶段的建议与实现保持干净的语义边界,这对使用大型语言模型辅助工程工作有很好的借鉴意义。 遇到的挑战与设计权衡 在构建极简系统时,如何平衡功能完整性与实现复杂度是一大挑战。选择 SQLite 而非分布式数据库降低了系统复杂度,但也意味着 Dubernetes 更适合单节点或本地测试场景而非生产级分布式集群。
使用 docker 命令行或本地 Docker API 简化了容器管理,但也将实现绑定到宿主机环境中。内置 nginx 作为 ingress 在简洁性上取胜,但牺牲了负载均衡策略与扩展能力。作者通过明确的设计范围与文档说明,让这些权衡变成项目的优点而非缺陷,使 Dubernetes 成为一个理想的学习平台。 实际运行与演示体验 运行 Dubernetes 非常直接:编译 Orchestrator 二进制并在宿主机启动,随后通过 dubectl apply 提交示例 YAML 即可看到后台的容器被创建和 nginx 配置被更新。通过 curl 模拟域名解析,可以直接访问服务并查看请求头中的转发信息。这样的即时反馈大大降低了学习曲线,对于希望理解从声明到运行的全流程的工程师尤其有帮助。
从教学角度的价值与扩展可能 Dubernetes 最显著的价值在于其教学意义。比起阅读大量概念文档,亲自动手搭建一个可工作的编排器更能培养工程思维。读者在实现过程中会遇到资源模型设计、并发安全、数据库事务、容错策略、外部依赖管理等现实问题,从而更容易理解成熟项目为何要设计成如今的样子。基于 Dubernetes 可以衍生出多个方向的扩展实验,比如增加健康检查机制、实现更灵活的 ingress 路由、引入调度策略把容器分配到不同节点,或者将持久化层替换成分布式存储以探索多节点编排。 如何开始上手并学习要点 对想要上手的开发者而言,先阅读项目仓库的 README 与示例 YAML,理解 PodSpec 的字段含义,然后在本地构建并启动 Orchestrator。接着创建一个小型 Web 应用镜像并通过 dubectl 部署,观察调和器如何创建容器与更新 nginx 配置。
如果遇到问题,查看 Orchestrator 的日志以及调和器与 docker 模块的交互是排查的关键。学习重点应放在期望状态与真实状态的比对逻辑、数据库操作的幂等性以及容器创建与端口管理的细节。 总结与展望 Dubernetes 并非对 Kubernetes 的替代,而是一把解构复杂系统的放大镜。通过极简设计、TDD 实践与可运行的示例,开发者能在短时间内把握容器编排的核心思想,并在此基础上进行更深入的实验与学习。项目同时展示了在实际工程中如何借助语言模型做为编码助理的有效工作流,从需求拆解到实现再到测试与文档更新,形成闭环。未来可在此基础上逐步引入调度、多节点支持和更完善的健康管理机制,逐步把实验平台向更真实的生产场景靠拢,但无论如何,保持简单与可理解性应始终是学习工具的首要目标。
。