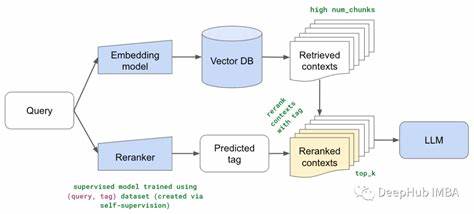
在当今技术飞速发展的时代,人工智能(AI)已经成为许多人关注的焦点。尤其是大型语言模型(LLM)如GPT系列,让人们感受到仿佛机器拥有了“理解”与“推理”的能力。然而,这些被称为“模式机器”的系统背后隐藏着大量未解之谜,它们究竟是如何工作的?我们又为何难以真正理解它们的内部机制?要解答这些问题,我们必须从基础说起,深入探讨模式识别的概念、神经网络的起源以及当代深度学习模型的内在结构。人类大脑本身就是世界上最复杂的模式识别机器。科学研究表明,我们的大脑通过成千上万亿的神经元网络,基于电信号进行信息交流,这种庞大而复杂的神经网络能够让我们识别面孔、语言甚至抽象概念。早在20世纪50年代,心理学家弗兰克·罗森布拉特就提出了一种称为感知器(Perceptron)的计算模型,模仿人脑神经元的活动进行简单的模式识别。
他的研究成为后续人工神经网络和深度学习发展的重要基石。尽管感知器起初让人们对机器智能充满期待,但到了1969年,人工智能领域的两位先驱马文·明斯基和西摩·帕珀出版了《感知器》一书,指出单层感知器存在无法解决的局限性,例如无法有效处理异或(XOR)问题。这项批评一度使神经网络研究陷入低谷。但随着计算能力的提升和多层神经网络结构的出现,这一局限被逐渐突破。多层感知器和非线性激活函数的引入极大增强了模型的表达能力,也为“深度学习”概念的诞生铺平了道路。现如今,深度学习模型由数十乃至上百层构成,能够捕捉语言和图像中极其复杂的模式。
以大型语言模型为例,GPT-3拥有近百层的神经网络,这种“深度”使其不仅能生成语法正确的文本,更似乎具备某种程度的语义理解和推理能力。虽然从外部看来它们的表现令人震惊,但实际上,我们对于模型中间层到底“学到了什么”仍无确切答案。研究人员只能通过间接手段,比如可视化技术或特征归纳,尝试揭示隐藏层中的信息编码,但真正的含义和机制依旧是个谜。这样的“黑箱”现象让学术界和工业界都面临挑战。我们习惯于通过科学模型来理解自然,但模式机器的运作方式更像是工程模型,它们被设计用来完成特定任务,例如预测下一个词,而不是帮助人们理解其内部规律。更有趣的是,通过预测文本的设计目标,模型意外地展现出人类般的推理能力。
这种现象令许多专家感到困惑甚至惊奇。语言学家艾米丽·本德和亚历山大·科勒通过提出“章鱼思维实验”,形象地说明了仅凭数据暴露并不足以真正掌握语言含义。这一点与大型语言模型训练方式形成对比,表明它们的学习原理与人类认知截然不同,因此用传统人类理解的方法解释这些模型往往会产生偏误。哲学家丹尼尔·丹尼特提出的“意向态度”理论在此处尤其具有启发意义。我们通常倾向于赋予语言模型类似于人类的思考和意图,这种心理投射其实是一种认知错觉,如同看到不存在的脸孔一般。这种“拟人化”既帮助我们与机器互动,又阻碍了深入理解它们的本质。
与此同时,设计态度也未能完全发挥作用。尽管我们知道模型是被设计来生成连贯文本,但其复杂的行为与设计细节之间的联系却极为模糊,这使得预测模型在特定情境下的表现变得困难重重。面对这些挑战,意外故障和系统边界的测试成为我们了解模式机器工作原理的珍贵窗口。正如心理学家赫伯特·西蒙所言,只有当系统超出负载极限时,我们才能发现其实际特性和潜在缺陷。然而,对于语言模型而言,看似“错误”的回答往往只是它们以“合理”形式完成既定任务的表现——生成看似正确但事实不符的内容。这种成功的“失败”揭示了我们认知与机器行为解读之间的鸿沟。
尽管它们具备强大的语言处理能力,这些模式机器的内在机制依然令人费解。我们既难以用传统的科学模型揭示其运行法则,也不能用简单的工程设计思维完全掌握其行为。它们的复杂性远超以往任何人工智能系统。未来,要真正破解这一难题,需要跨学科合作,结合神经科学、认知心理学、计算机科学和哲学,开辟新的研究路径。同时,提升模型的可解释性,开发更透明的算法,将帮助我们减轻“黑箱效应”,推动人工智能朝着更加可信和安全的方向发展。模式机器的神秘面纱尚未完全揭开,但它们的出现正深刻改变人类的生产、生活和认知方式。
唯有持续探索与创新,才能逐步理解这些复杂系统的内在规律,进而充分发挥它们在未来社会中的巨大潜力。