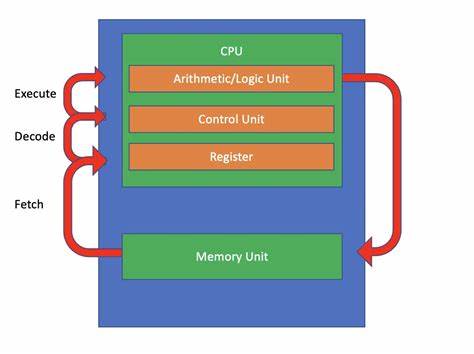
在现代计算机体系结构中,CPU分支指令起着至关重要的作用,直接影响程序的执行流程和性能表现。分支指令使程序能够基于条件判断实现不同代码路径的选择,是实现决策逻辑的基础。理解分支指令的原理和应用,对于程序开发者尤其是关注高性能计算的工程师而言,有着重要的意义。 程序通常遵循顺序执行模型,这意味着CPU一条一条顺序执行指令,默认情况下执行下一条紧跟当前指令的内存地址指令。然而,分支指令能够打破这种线性顺序,跳转到程序中另一个指定位置,形成非线性控制流。分支指令根据不同条件选择是否跳转,称为条件分支;或直接无条件跳转,称为无条件分支。
理解这两类分支能帮助程序员更准确地把控程序执行流程。 无条件分支指令总是执行跳转,常见于函数调用、返回以及循环控制结构中。比如函数调用需要跳转至函数体的入口地址,函数返回则跳转到调用点之后的指令。循环结构往往依赖无条件分支实现迭代,当循环体执行完一次后,程序通过跳转回循环起始位置继续判断是否满足继续执行的条件。无条件分支的特点是跳转地址提前已知,通常直接编码在指令中,以相对偏移的形式表示跳转位置,保证指令长度紧凑且执行效率高。 条件分支则更为复杂,仅当满足特定条件时跳转,否则继续执行下一条顺序指令。
条件的判断基于CPU状态寄存器中的标志位,如零标志、进位标志、负号标志及溢出标志,或直接比较寄存器值与常量、内存数据。CPU常通过专门的比较指令设置相应标志位,随后条件分支指令判断标志位确定是否跳转。条件分支是程序实现分支逻辑的核心,如if语句、while循环中的条件判断皆依赖于此。编译器则根据程序上下文和优化策略,将高级语言条件逻辑转化为相应的条件分支指令。 分支指令又分为直接分支和间接分支。直接分支的目标地址包含在指令本身,通常作为相对偏移量,方便实现短距离跳转,节省指令码空间。
间接分支的目标地址则存储在寄存器或内存中,需要在执行时读取,适合函数指针调用或基于虚函数的多态调用等动态跳转场景。间接分支由于跳转地址动态变化,难以预测,带来了更大的性能挑战。 现代CPU为提升流水线效率,广泛引入分支预测技术,针对分支指令进行预测执行。分支预测旨在猜测分支是否会被执行(跳转)以及跳转目标,以提前加载可能的指令路径,避免因分支跳转的指令无法提前获取而导致的流水线停顿。当预测正确时,CPU能够保持高速流水线运行;如果预测错误,CPU须舍弃错误路径的执行结果,重新加载正确指令,浪费时间和资源。分支预测准确率对整体性能影响巨大,尤其是分支频繁的程序中更为关键。
经典的分支预测方法包括静态预测和动态预测。静态预测基于固定规则,比如循环中的条件常预测为跳转,简单直观但适应性差。动态预测则通过维护历史分支执行记录,使用分支历史表或分支目标缓冲区,根据过去的行为预测未来的走向。这类方法能显著提升预测准确率,现代CPU的分支预测准确率可达到90%以上,大幅减少流水线停顿带来的性能损失。 另一方面,程序设计者通过编写高质量代码也能优化分支相关性能。减少复杂条件表达式,避免多个冗余的条件判断,可以减少分支指令数量。
结构化的代码设计和合理的函数划分,有利于编译器优化,减少间接分支调用和递归深度。特别是在循环体和频繁执行路径中,避免多重分支嵌套和不必要的内存访问,有助于CPU更高效地进行指令流水线操作。 同时,利用编译器内联功能,将函数代码展开到调用处,可以消除函数调用的分支开销,提升代码局部性和可优化性。内联后的代码更容易进行常量传播、死代码消除等优化,减少无用分支和额外判断。开发者应关注编译器优化参数,确保关键函数能够被有效内联,以获得更好执行效果。 此外,现代指令集提供了条件执行指令,如条件移动或选择指令,允许在不发生分支跳转的情况下根据条件更新寄存器数值。
合理使用这些指令,有助于替代小型条件分支,避免分支预测失败带来的性能惩罚。 在实际开发中,还需注意避免深层次调用堆栈过长,因部分CPU内部设计有限大小的返回地址栈,递归调用或多级库函数调用可能导致该结构溢出,带来更多的返回地址预测错误,降低整体性能。保持调用链简洁、合理设计层次结构,是提升性能的良好实践。 综上所述,深入理解CPU分支指令的类别、工作原理以及基于硬件的分支预测机制,是优化程序性能的关键所在。开发者在编程时,需考虑如何编写易于预测执行的代码,减少分支跳转和间接分支的使用,同时利用编译器优化和条件执行指令提升代码效率。随着CPU架构不断演进,分支预测技术也在持续进步,但写出结构清晰、分支合理的代码依然是提升软件性能的根本。
掌握了这些知识,软件开发者不仅能理解程序在CPU上运行的底层机制,还能在编写代码时做出更明智的设计选择,让性能发挥到极致。未来,在多核和异构计算加速的趋势下,分支指令优化依然是软件性能调优不可或缺的重要领域。