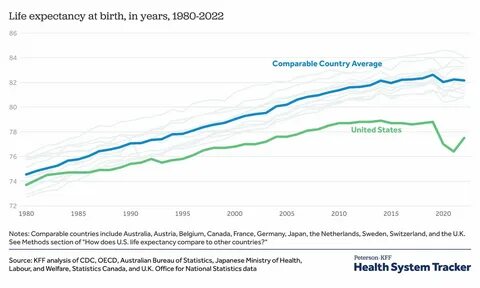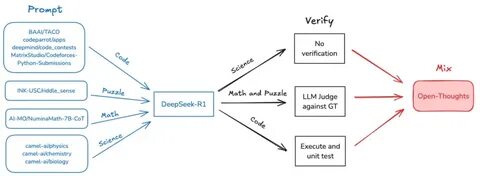
近年来,理论深度学习领域涌现出大量研究聚焦于神经网络在无限宽度极限下的行为,这一视角虽初看似乎不切实际,却为理解神经网络的训练机制带来革新性的理论工具。神经切线核(Neural Tangent Kernel, NTK)正是在这种极限下诞生的关键概念,它将复杂的非线性神经网络转化为线性模型,从而极大简化了梯度下降算法的分析和理解。本文将围绕NTK展开深入探讨,阐述其数学背景、训练动力学、应用及局限,帮助读者全面把握这一前沿理论。神经切线核的起点是考虑一个带有权重参数的神经网络函数f(x,w),其中x为输入,w为权重参数向量。将训练数据的预测输出统一表示为y(w)时,最常见的损失函数便是均方误差损失,目标是在权重空间通过梯度下降将预测误差逐步消除。神经网络因非线性复杂,直接分析训练过程充满挑战,然而当网络宽度m趋向无穷时,权重的变化在训练期间趋于微小,网络表现出“懒惰”学习特性,这促使我们可以采用泰勒展开将非线性函数线性化,即利用网络在初始化点的梯度信息对其进行线性逼近。
这种线性模型的特征映射便是网络输出对权重的梯度,而由此导出的核函数——神经切线核——编码了输入空间的相似性关系。直观上,大宽度网络中由众多神经元共同决定输出,因此单一神经元权值的小幅调整即可实现训练目标,从而保证了线性近似的准确性。理论分析中,一个关键量化指标 \kappa(w_0) 用以衡量训练中网络雅可比矩阵的相对变化率。随着宽度增加,这一指标趋近于零,表明网络训练轨迹紧贴其线性化模型。此外,通过适当调整模型输出的缩放因子,通过增大该因子同样可以实现模型的线性化,此即“懒惰训练”理论的核心思想之一。训练中采用微小的学习率时,梯度下降过程可视作梯度流(gradient flow),其连续时间描述为权重向梯度方向的负移动。
将梯度流作用于网络输出可得函数空间中的动态方程,其核心是NTK矩阵的作用:输出误差的演化满足关于NTK的线性微分方程。因在懒惰训练条件下NTK保持不变,训练过程成为一个线性动力系统,训练误差以NTK的特征值决定的速率指数衰减,最终保证训练误差收敛为零。此线性动力学模型不仅简化了分析,也为理解训练收敛性提供了坚实理论基础。在实际神经网络训练中,NTK体现为权重梯度特征映射的内积矩阵,是一种数据驱动的核方法,将神经网络训练解析为核机器学习范畴。理论上,利用谱分解技术可以将学习过程解耦为一组独立的特征模式,各自按对应的特征值速率收敛。网络宽度趋向无穷时,NTK本身变为确定性,避免了随机初始化带来的不确定性,进而使无限宽度神经网络具备固定的内在训练核。
这一特性为NTK计算与模拟提供了理论基础,也促进了基于NTK构建相关算法的发展。尽管NTK理论在训练动态图像和数学证明上具有强大说服力,实验证实实际的过参数化神经网络往往跳脱了纯粹kernel regime,体现更丰富、非线性的学习行为。NTK线性化模型通常在标准视觉任务如MNIST和CIFAR中表现领先于传统机器学习方法,但仍落后于完全训练的深度网络。原因在于非线性调整及模型内部复杂结构被忽略,使得NTK所描述的模型泛化能力受限。当前学界也正探索结合最优传输和均值场理论的非线性动力学,试图补全NTK理论不能涵盖的宽度有限网络性能,为深度学习理论注入新的活力。此外,训练收敛为零训练误差的结果也对理解神经网络泛化机制带来启示。
梯度下降在内核空间中选择的最小范数解对应于输入到特征映射空间中范数最小的函数,这种隐式正则化有助于解释深度模型的良好泛化性能。深入研究NTK与再生核希尔伯特空间等数学工具的联系,有望揭示更多训练与泛化的奥秘。综上,神经切线核作为桥梁连接深度神经网络和核方法,为理解无限宽度网络提供了清晰框架。它不仅极大简化了非线性模型的训练分析,还揭示了宽度与训练稳定性之间的紧密关系。尽管实际应用中存在局限和差异,NTK仍是理论深度学习的重要突破,推动我们向全面揭开神经网络训练黑盒迈进。随着研究的深入,结合NTK与非线性、宽度有限效应的混合理论将成为必然趋势,为人工智能发展提供更坚实的理论支撑和技术指导。
。