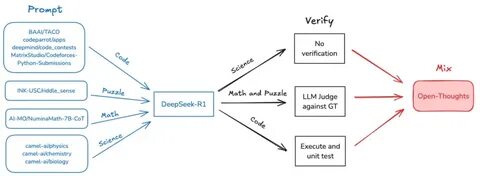
推理模型作为人工智能领域的关键组成部分,近年来在数学、编程和科学推理等多项任务中取得了飞速进展。然而,绝大多数顶尖模型往往依赖于私有且难以获取的数据集,导致研究透明度受限,训练复现难度增大,制约了行业整体的创新与发展。在这样的背景下,OpenThoughts项目应运而生,旨在通过构建公开、可复现的数据集配方来重塑推理模型的训练生态,为科研和工业应用提供更加坚实的数据基础和开放的研究平台。OpenThoughts作为一个开源项目,致力于创造开放且高质量的推理数据集,极大提升了推理模型训练的可访问性和可验证性。项目团队首先推出OpenThoughts2-1M数据集,基于公开数据打造了OpenThinker2-32B模型,成功在包括AIME(美国数学竞赛)和LiveCodeBench等标准推理基准上实现与领先私有模型DeepSeek-R1-Distill-32B的持平表现,向业界证明了开源数据在推理模型训练中的潜力与可行性。OpenThoughts进一步推动数据生成流程的系统化优化,通过超过一千次的受控实验深入分析数据生成每个环节的影响,形成更精细、更高效的OpenThoughts3版本。
这一版本的数据集规模扩展至120万条示例,并引入了QwQ-32B作为教师模型,成功预训练出OpenThoughts3-7B,模型在2025年度的多项重要推理评测中取得突破性进展。具体而言,OpenThoughts3-7B在AIME 2025考试中达到53%的准确率,在LiveCodeBench 06/24-01/25测试中获得51%,而在GPQA Diamond基准上实现54%,分别比DeepSeek-R1-Distill-Qwen-7B提升了15.3、17.2和20.5个百分点。这些显著的性能提升不仅昭示了数据质量与数据生成流程优化对推理能力的重要作用,更强化了开源数据在推动AI模型发展的战略价值。推理能力的提升离不开严格设计和控制的数据生成流程。OpenThoughts团队通过系统实验调查了数据来源、示例构造、答案验证、噪声处理、提示工程等多维度因素对模型性能的影响。该方法论不仅优化了训练数据的效用,还构建了可持续扩展的生成管线,为后续更大规模模型的训练奠定了基础。
同时,项目的开源策略有助于聚合全球顶尖研究力量,使数据和模型的共享成为可能,加强了跨领域合作与知识传播,推动推理技术朝着更加公平和开放的方向发展。从技术角度来看,OpenThoughts倡导“数据为王”的理念,强调数据配方的科学制定与量化评估。通过系统化设计生成策略和严谨实验,团队精确调控了训练数据的多样性、准确性和代表性,确保模型在处理复杂推理任务时能够展现出真实、稳定的推理能力。此外,结合教师模型指导训练,进一步提升了新模型对复杂逻辑和多步骤问题的理解能力。当前人工智能发展的关键趋势之一,便是推动模型从海量数据中学习更深层次的推理和理解,这正是OpenThoughts专注的核心。借助公开且丰富的训练数据,OpenThoughts项目不仅使得训练推理模型的门槛大幅降低,也极大促进了新技术、新方法的快速验证和迭代。
对于学术界而言,这意味着研究人员可以更自由地探索创新算法和结构;对于工业界,则推动了推理智能应用的广泛落地和优化。此外,OpenThoughts所实现的模型在数学竞赛、编程任务以及科学推理等多领域的优异表现,预示着它将成为AI助力教育、科研和工程诊断的重要工具。例如,在数学教育领域,能够准确理解和推理复杂题目的模型将帮助学生更系统地掌握知识点;在编程自动化领域,高质量推理能力则确保代码生成和错误排查更为精准可靠;而在科学领域,辅助研究者进行跨学科逻辑推演将显著提升科研效率和创新水平。总的来说,OpenThoughts项目的成功体现了开源数据在推理模型训练中的巨大潜力。通过科学的数据策略、系统性实验和高效的模型训练,项目不仅突破了依赖私有资源的瓶颈,还推动了推理能力在人工智能领域的技术革新。未来伴随着数据集规模的进一步扩大和模型架构的持续优化,OpenThoughts无疑将成为推理模型研究和应用的重要基石,促进人类与机器智能的深度融合与协同发展。
。