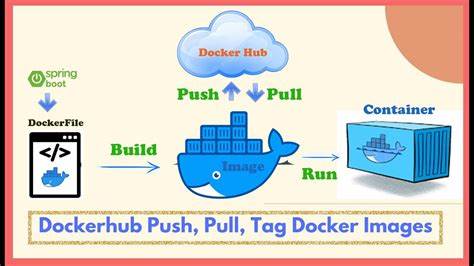
随着容器技术的普及和云计算的迅猛发展,Docker已成为全球开发者和运维人员首选的容器平台。在Docker生态中,Docker Hub作为主要的容器镜像仓库,承担着存储、分发成千上万镜像的重要任务。然而,近期Docker Hub用户反馈在镜像拉取和推送过程中遇到了若干问题,引发业界的广泛关注。本文将深入分析这些问题的根源,探索排查思路,分享应对之道,帮助从业者从容应对类似挑战,保障项目的稳定运行和高效交付。 Docker Hub实行全球化架构,为多地区用户提供便捷的镜像访问服务。任何仓库的服务稳定与否,直接影响研发节奏和生产环境部署的流畅性。
近期Docker官方也发布了关于拉取和推送中部分请求出现异常的公告,特别是在2025年6月4日至6月5日期间,用户多次遇到失败提示及“301 Moved Permanently”HTTP状态码。该错误通常出现在资源请求被重定向时,说明镜像存储的位置或访问路径发生变更,导致客户端无法正确完成文件上传或下载。 此类故障对于依赖自动化流水线和持续集成(CI/CD)的团队而言,无疑是巨大的挑战。镜像推送失败会导致新版本无法及时发放,拉取失败则可能引发线上服务异常或中断,直接影响用户体验。为此,Docker官方迅速响应,开展全面调查。根据事件时间线显示,2025年6月4日上午,运维团队检测到异常后立即进入排查状态,并在中午前部署了针对性改动,通过改进访问策略和资源定位机制尝试缓解问题。
随后故障得到明显缓解,官方持续监控24小时后确认问题解决,服务恢复正常。 分析此次事件,关键障碍集中在Docker Registry与Cloudflare CDN的交互过程中。Cloudflare作为内容分发网络(CDN)承担加速访问,同时也负责资源缓存与安全防护。然而在推送镜像层(layer blob)写入时,HEAD请求收到301重定向响应,表明存储节点或URL路径配置存在不一致,导致客户端访问地址与资源实际位置不匹配,造成请求失败。出现此类问题通常与动态存储调整、缓存刷新或访问权限变更有关,反映了云端服务架构的复杂性和运维管理的难度。 面对这类问题,开发者和运维人员可采取多重策略保障业务连续性。
首先建议紧密关注官方Docker状态页面及相关公告,及时获得异常信息及恢复进展,避免盲目排错。此外,使用本地私有镜像仓库作为备选方案,有助于在公共服务中断期间维持镜像的部署和更新,保障核心应用的稳定。在镜像管理层面,合理设计镜像构建与分发流程,避免单点依赖,以及优化镜像大小和层次结构,也能在一定程度上减少拉取和推送中断带来的影响。 从技术角度讲,理解Docker Registry协议和其与CDN配合的工作机制,对快速定位此类问题至关重要。规范拉取推送操作,确保网络环境的稳定和访问路径的正确性,是降低故障风险的基础。对于企业级用户,构建多地多节点的镜像同步方案,结合镜像加速器服务,能显著提升访问速度和容灾能力。
同时,加大人工智能及自动化监控系统的投入,利用异常检测与预警机制提前捕获潜在故障信号,将是未来云端容器服务发展的关键方向。 从Docker官方处理事件的过程可以看出,面对互联网规模的服务挑战,及时响应和透明通报同等重要。用户只有在获得充分信息支持时,才能调整策略,合理分配资源,保障项目进度不被拖延。事件发生后,官方不仅详细发布问题排查结果,还分享了修复方案和后续监控措施,体现了持续优化用户体验的决心。 与此同时,用户层面应重视镜像安全和访问稳定性的双重保障。合理配置权限控制,避免不必要的访问重定向,结合强身份认证和网络策略,既防止潜在攻击,又提升服务健壮度。
对于个人开发者,熟悉Docker命令参数和调试技巧,能够快速识别网络请求异常,及时调整镜像源配置,保障开发环境的高效运转。 展望未来,随着容器技术生态的不断扩展,镜像仓库的服务压力及复杂度只会持续提升。Docker Hub作为业界重要基石,必然投入更多资源进行系统架构优化,提升访问稳定性、缩短延迟、增强安全能力。同时,混合云、多云环境的兴起,也促使企业构建更灵活多样的镜像管理策略,实现跨平台无缝部署。技术创新和社区协同将成为推动行业持续进步的动力。 综上所述,Docker Hub拉取和推送过程中出现的异常虽然给用户带来不便,但也揭示了云原生环境下分布式存储和访问管理的复杂性。
借助官方快速响应能力和丰富的经验积累,用户可以系统性提升自身容器基础设施的弹性和安全性。持续关注服务动态,科学设计镜像使用策略,配合合理的运维手法,必将助力开发者在未来复杂多变的技术环境中稳健前行,实现应用的高效交付和持续创新。