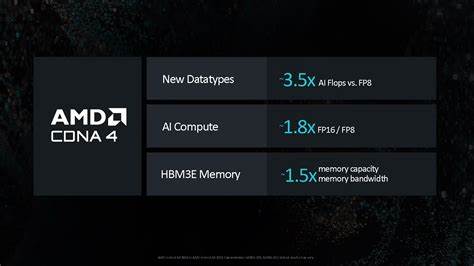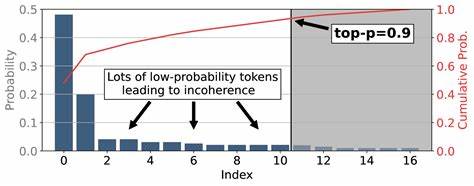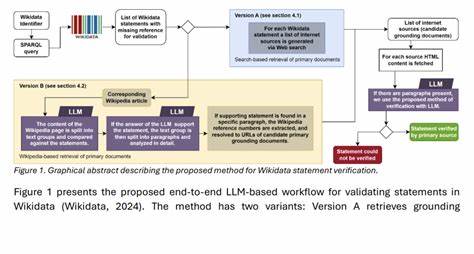
随着人工智能和自然语言处理技术的迅猛发展,海量非结构化文本信息的高效理解与组织成为业界关注的重点。知识图谱作为语义信息组织的重要手段,能将分散的数据通过实体和关系构建成网络,极大提升数据检索和智能推理能力。然而,如何准确地从文本中抽取出语义三元组,成为实现知识图谱构建的关键挑战。OntoCast应运而生,作为一个结合大型语言模型(LLMs)与共演本体的代理式框架,致力于从各种文档中自动提取RDF三元组,推动知识图谱的智能构建和语义应用的普及。OntoCast框架的核心优势在于其融合了本体驱动和语言模型辅助的抽取方法,确保了语义的一致性和动态演化能力。传统的文本抽取技术往往面对领域知识缺失、语言歧义和上下文理解不足等问题,导致提取的三元组准确性受限。
OntoCast采用本体引导的设计理念,利用预先建立的领域本体作为语义蓝图,通过搭载先进的LLMs如OpenAI GPT-4等模型,能够深度理解文本语义,识别实体及其属性关系。同时,框架通过不断调整和完善本体结构,实现本体的协同进化,与抽取的知识相辅相成,保持对领域知识的持续更新和优化。在具体实现上,OntoCast支持多种数据格式,包括纯文本、JSON、PDF和Markdown文档,具备良好的格式兼容性和扩展性。文本首先经过语义切分,将长文本拆分成若干语义上连贯的块,便于模型逐段理解与分析。随后,框架基于选择的本体模板执行本体处理和语义抽取,利用LLM生成符合RDF标准的三元组,完成文本向结构化知识的转化。OntoCast同时支持RDF三元组的多种序列化输出格式,诸如Turtle,方便与主流三元组存储系统的无缝对接。
为了方便知识图谱的存储与检索,OntoCast提供了对Fuseki和Neo4j等主流三元组存储平台的集成支持,用户可选择适合自身需求的后端服务,实现知识的持久化管理和高效查询。此外,OntoCast实现了实体消歧义功能,能够解决跨文本、跨切片的同名实体指代问题,确保知识图谱中实体的准确唯一性。这为构建高质量、连贯性的知识网络奠定了基础。该框架还特别注重可配置性与易用性,通过环境变量配置和RESTful接口,用户能够灵活指定语言模型、API密钥和服务器端口等参数。其REST API支持上传文本或文件,并返回包含提取事实、更新本体及处理元数据的JSON响应,使得集成与二次开发更加便捷。OntoCast不仅局限于知识图谱构建的基础应用,也为语义搜索和基于知识图谱的问答系统提供了强大支撑。
通过将结构化知识与生成模型结合,用户可实现基于图谱的检索增强生成(GraphRAG),显著提升问答的准确性和上下文理解能力。此外,OntoCast助力本体管理的自动化,通过对提取结果的本体评估与批判,持续调整本体结构与属性定义,促进本体的自动生成、验证和完善,从而应对快速变化的领域知识需求。在数据整合方面,OntoCast框架能够融合来自不同来源、多种格式的非结构化数据,将它们统一映射到语义图谱,解决数据孤岛问题,推动跨领域信息共享与互操作。安装与运行OntoCast相对简单,用户可通过pip直接安装或使用提供的Docker镜像部署。配置环境变量后,即可启动服务器,利用兼容各种输入格式的API接口随时提交文本供处理。在未来发展规划中,OntoCast团队计划持续优化三元组序列化支持,增强对Fuseki和Neo4j的集成深度,同时引入更加先进的本地图检索工具,提升抽取模型的效率与准确率。
作为一个开源项目,OntoCast欢迎社区贡献和协作,不断推动语义Web技术和知识图谱构建的边界。总的来看,OntoCast凭借其创新的本体驱动与大语言模型融合机制,为自动语义三元组提取提供了全新的解决方案。它不仅突破了传统抽取方法的局限性,提高了语义一致性和知识准确度,还增强了本体的适应性与演化能力。此框架的广泛兼容性和易扩展性,使其适用于多种应用场景,包括知识图谱构建、语义搜索、问答系统和数据整合等。在大数据与人工智能交叉快速发展的时代,OntoCast为文本智能理解和知识管理提供了强有力的技术支撑,助力实现更加智能化的知识发现和利用。随着技术的进步和社区的拓展,OntoCast有望在未来成为知识图谱领域的重要基石,推动智能信息处理迈向新的高度。
。