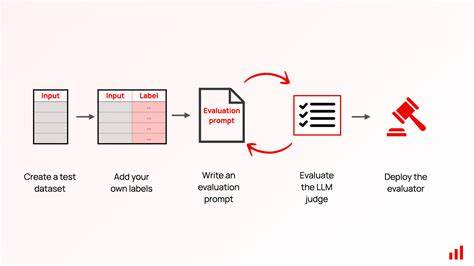
随着人工智能技术的快速发展,基于大型语言模型(LLM)的应用日益广泛,从内容生成到对话系统,AI的表现越来越受到关注。如何有效评估和保障这些模型输出的质量,成为业界亟待解决的重要问题。传统评估方式往往依赖人工审核,耗时费力且难以规模化,因此,利用大型语言模型自身作为自动评判者(LLM-as-a-Judge)成为评估领域的创新突破。利用LLM作为评判者不仅提高了评估的自动化程度,还在速度、精确度和一致性上具备显著优势,为构建稳定可信的AI应用奠定了坚实基础。掌握这种评判机制的核心要素,有助于提升AI模型的可靠性与用户体验,推动智能系统的稳健发展。通过深入理解和应用LLM评判者技术,开发者能够实时捕捉模型输出中的质量问题,有效识别并缓解常见的偏差,如冗长表达、权威倾向及位置偏好等,从而保障生成结果的公正性和多样性。
实现这一目标需要结合多种高级技术手段,包括链式推理(Chain-of-Thought),令评判过程更具逻辑性和透明度;利用逐词评分(Token-level scoring),细粒度判断文本质量;以及进行成对比较(Pairwise comparisons),对不同输出进行相对评价。掌握这些技术不仅提升了评判者的智能和精准度,也为进一步的模型训练与优化提供了定量依据。在实际构建过程中,从框架设计到代码实现,每一步都应注重系统的灵活性与扩展性。开发者需要搭建一个可复用且易于调整的评判流水线,集成多种评分机制,并确保结果具备可解释性,方便后续调优与管理。此外,评判系统还应支持快速集成到现有的AI应用环境中,实现无缝对接与实时监控。有效使用LLM作为评判者还能促进AI开发流程的闭环反馈。
通过自动化评估及时发现模型失误,例如偏离主题、逻辑矛盾或表达错误,团队能够快速响应并针对性地改进训练数据和算法设置,显著降低模型缺陷的数量和影响范围。同时,多样化的评判视角和严格的验收标准能够提升系统整体的鲁棒性,打造更具竞争力的智能产品。确保评判者本身的质量同样重要。评判模型需要经过充分训练和验证,避免自身生成偏差影响评分结果。例如,某些模型可能存在偏爱长篇内容的倾向,或在面对模糊指令时表现不稳定。通过设计多阶段验证流程和随机化测试,可以有效规避这类风险,提高评判标准的公平性与准确性。
当下,随着相关研究和技术逐步成熟,掌握大型语言模型作为自动评判者的实践能力,已成为提升AI生态竞争力的重要路径。众多领先企业和科研机构纷纷投入资源,开发专业的评判平台和工具,并提供丰富的文档和案例支持,帮助用户快速上手并实现自定义方案。除此之外,业界社区活跃,在线分享诸多实用经验和代码资源,极大地促进了知识传播与创新应用。展望未来,LLM-as-a-Judge技术将继续与生成模型深度融合,推动更加智能、透明和可信的AI系统诞生。结合交互式评判和人机协作机制,评估结果的精准度和解释性将进一步提升,助力构建真正符合人类价值观和需求的人工智能服务。综上所述,掌握如何利用大型语言模型作为自动评判者,从理论到实践全面提升AI质量管理能力,是迈向智能化应用新时代的关键。
通过建立系统化、科学合理的评判体系,结合技术创新与持续优化,人工智能的潜力将得到最大释放,赋能各行各业实现数字化转型升级。