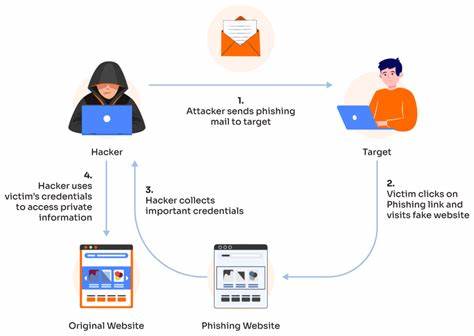
点积运算是许多计算密集型任务中的基础操作,尤其在图像处理、机器学习和科学计算领域有着广泛应用。传统观念认为内存数据的对齐是实现高性能计算的关键,错位数据访问(即未对齐的内存访问)通常被认为会导致性能严重下降。然而,随着现代处理器设计的演进,这一观点正在逐渐受到挑战。本文将深入探讨点积运算中错位数据访问的影响并结合最新实测数据进行分析,帮助开发者更科学地理解内存对齐问题,从而有效优化代码性能。 点积运算简单来说,就是对应元素相乘后进行累加求和。它广泛运用在向量计算、矩阵运算等场景中。
理想情况是参与运算的数据在内存中紧凑且按元素大小对齐,这样处理器能够高效地进行数据读取和计算。未对齐数据指的是数据元素没有存储在其固有字节宽度的倍数地址上,例如一个4字节浮点数存储在地址0x1001而非0x1000。未对齐访问在某些架构上可能导致异常或性能下降,也容易触发内存访问错误。 传统观点认为,未对齐数据访问会导致CPU在读取数据时跨越多个缓存行甚至内存页,从而增加缓存未命中和内存访问延迟,影响整体表现。实际情况其实复杂得多。现代处理器通过大量硬件优化来缓解未对齐访问带来的性能开销。
例如,支持高效的缓存行加载机制、执行负载合并、流水线调度改进以及利用SIMD指令集等技术,使得即使在不理想对齐情况下,数据访问也可以保持较高性能。 知名性能专家Daniel Lemire在其博客中发布了针对错位数据点积的现代表现测试,该实验基于ARM NEON和Intel AVX2等SIMD指令集,选取Apple M4和Intel Ice Lake两个平台进行对比测试。测试中使用了两个大小约1MB的32位浮点数组,分别在不同字节偏移量下执行点积操作,考察未对齐访问对每个浮点数平均执行时间、指令数以及每周期执行的指令数量的影响。 值得注意的是,实验结果显示,在Apple M4处理器上,错位访问对性能的影响非常有限,最高也仅体现出约10%的时间差异;在Intel Ice Lake处理器测试中,几乎难以观察到任何性能差异。这意味着现代处理器对未对齐内存访问的优化已极为成熟,程序员无需过分纠结对齐问题对点积性能的负面影响。 此外,Daniel Lemire还说明,尽管部分情况下未对齐访问可能伴随跨越两个缓存行,造成少量的周期惩罚,但实际效果难以显著影响整体程序性能,更不用说在大量计算和缓存优化的综合优化情境下,这些影响的比例被进一步抵消。
更先进的AVX-512指令集在宽寄存器下的测试也验证了这一结论,未对齐访问对性能的损害没有明显增加。 当然,数据对齐依然有其特殊意义。某些情况下,比如实现底层内存复制函数、执行原子操作或多线程同步时,必须保证操作的数据对齐以满足硬件指令的要求或达到线程安全。Intel提出的4K别名问题是一个典型的例子,高度特定的地址别名可能误导CPU预测和缓存行为,从而导致性能波动和数据一致性问题。此外,未对齐访问在一些老旧处理器或嵌入式系统中仍可能引起异常甚至程序崩溃。 然而,对于日常应用特别是数值计算和多媒体处理而言,现代CPU的容错与优化机制使得未对齐数据访问在性能上已经不再是核心瓶颈。
程序员若花费大量时间为某些算术密集型操作严格对齐内存,可能并不能带来预期的加速效果。相反,更多的性能收益应关注算法优化、缓存使用模式和SIMD指令的合理利用。 数据布局和内存访问模式对总体性能的影响仍不可忽视,未对齐可能导致更多的缓存未命中或拉长访问延迟,尤其在数据访问分散或大规模数据操作时。但这些问题更多源于内存访问局部性和缓存策略,而非单纯对齐问题本身。Daniel Lemire的实验选择使测试数据大小控制在1MB,一方面避免了RAM瓶颈影响,另一方面确保缓存系统的有效利用。 令人感兴趣的是,实验中的反馈评论对测试方法提出了建设性意见,例如增加多累加器以提升乘加循环效率、调整测试数据规模减少缓存压力以及关注浮点数范围以避免出现次正规数和NaN值可能带来的性能变量。
这些都说明性能测试应该纳入多方面考虑,避免单一因素造成误导。 综上所述,点积和类似的矢量计算中,尽管传统理论强调内存对齐对于性能至关重要,现代CPU架构的硬件优化已经使得未对齐访问性能损失微乎其微。针对错位数据,开发者可以更加宽容,对对齐的过度担忧可以适当放松。优化重点应转向算法设计、缓存优化以及利用现代SIMD指令集的特性。同时仍需注意特殊编程场景中对对齐的要求,例如并发程序的原子操作和内存屏障操作。 不同架构和应用可能存在细微差异,但现有证据表明合理避免极端未对齐访问即可。
在实际开发中,优先保证代码清晰和可维护性十分关键,而不应为微小的对齐优化牺牲代码的灵活性和可扩展性。丹尼尔·勒米尔的研究为广大程序员提供了宝贵参考,促进了对硬件细节的理性认识,鼓励大家用数据和实验指导优化实践,而非依赖陈旧或片面的理论假设。 未来随着处理器设计继续升级,针对内存访问的智能预取、多级缓存优化和硬件并行执行能力不断增强,内存对齐的相对重要性或将进一步下降。程序员在性能优化时,应结合各自应用场景和实际测试结果,灵活调整优化策略,发挥底层硬件最大潜力。通过合理处理错位数据的点积运算,可以在确保准确性的前提下追求更高的运行效率,推动更广泛的应用领域取得突破性进展。