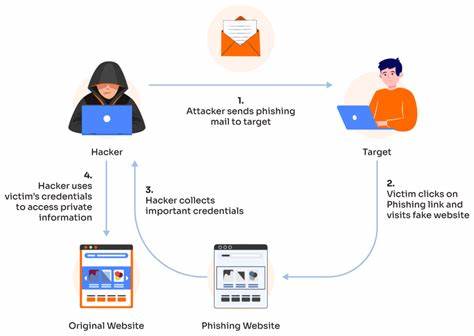
自2014年Kingma和Ba提出Adam优化器以来,该算法凭借出色的性能和适用性迅速成为神经网络训练的主流选择。尽管期间涌现出许多针对Adam及其变体的改进和创新,尤其是2017年引入的AdamW,其借助解耦权重衰减机制有效缓解了模型正则化问题,优化效果得以提升,但总体而言,没有任何一种新算法真正撼动Adam在大规模神经网络优化领域的统治地位。然而,近年来这一局面开始悄然改变,尤其是在大规模变换器模型训练的实践推动下,首次出现了突破AdamW瓶颈的迹象,引发行业内对一阶优化器新纪元的热议。 这场变革的核心动力在于优化研究从追求理论上的遍历性提升,转向以实践为导向,专注于特定应用场景——即大型变换器模型的训练需求。通过大量以训练稳定性、速度和泛化表现为指标的经验实验,研究者们逐渐摸索出适配这些深度学习巨型模型的优化策略。这种“务实至上”的研究范式不仅显著加快了优化技术的迭代速度,也促使理论探讨与工程实践相辅相成,共同推动优化算法的整体进步。
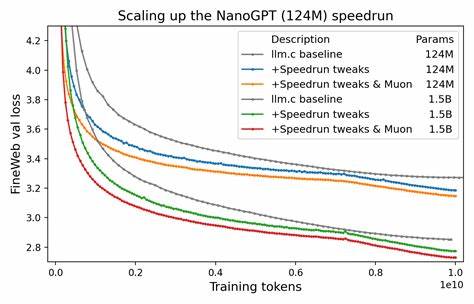
Moonshot公司近期在其标志性Kimi K2模型训练发布博客中,着重强调采用非AdamW优化器在规模高达万亿参数的大模型训练中的稳定性优势。这一公开声明成为推动优化算法重新审视的催化剂,表明在极端超大规模训练任务中,AdamW并非最佳选择。此外,Muon优化算法的崛起进一步证明了针对特定任务量身定制的优化器具有巨大的应用潜力。Muon在NanoGPT模型训练中展现出明显的速度优势,且凭借实际训练Token数作为横轴指标提供了更符合训练本质的效率评估视角,极大增强了其在业界的认可度。 随着Muon优化算法成功挑战AdamW的地位,引发了社区围绕其设计理念和实现细节的深入讨论。Muon强调对神经网络结构和训练机制的细粒度理解,结合实验反馈持续调整算法参数,使其能够更有效地适应变换器模型的训练动态。
更有研究者提出以Muon为基础,开发Gluon等优化框架,进一步巩固和扩展了其影响力。与此同时,另一些团队则采取独立的实验驱动路径,通过白化变换等新颖手段改进优化流程,推动算法在收敛速度和泛化能力方面达到新高度。 这些经验主义研究不仅带来了优化性能的实质进步,也促进了理论层面的突破。传统观点认为,理论分析与实验验证往往存在割裂,过度专注经验可能导致理论层面停滞。然而,目前的案例恰恰表明,经验反馈反而帮助研究者迅速锁定问题核心,深化对优化机制的理解。例如,Muon关键研发者Jeremy Bernstein通过在GPT训练速度跑实验中获得的洞见,提出了澄清许多一阶优化器关键理论的问题,令传统教科书中含糊不清的部分得以明晰展现。
这种“实验驱动理论发展”的范式成为当前优化研究颇具特色的新趋势。 此外,SPlus等优化方法同样秉持结合实验与理论的策略,在优化训练效率的同时,也力图以简化的数学工具揭示算法本质,推进理论体系的完善。它们公开承认改进方案主要产生于反复试验与反馈,而非单纯的数学推演,强调理论与实验是相辅相成的路径。该做法有效促进了算法结构的理解与优化,堪称现代优化算法研究的典范。 回顾AdamW的辉煌,我们可以说,它的成功得益于适应了早期深度学习中网络规模相对较小、硬件资源有限的环境需求。随着计算能力和数据规模的爆发性增长,大型变换器模型需要优化器在数千亿甚至万亿参数规模下保持稳定、高效的训练表现。
传统的通用优化器难以满足此类极端条件下的多重需求,尤其在处理巨量训练数据的泛化和收敛效率上表现出一定局限。因此,针对具体任务和模型架构设计的专用优化器成为必然趋势。 面对神经网络训练日益复杂且苛刻的要求,经验驱动的探索路径展现出显著优势。以超大规模训练为场景,研究者通过大量的实验验证找出算法在实践中的瓶颈与潜力,持续优化权重更新规则、学习率调度机制和动量策略,贴近现实训练环境的动态,最终获得比传统AdamW更出色的训练速度和稳定性表现。这一过程不局限于理论模型的简化假设,而是真正服务于实际工程需求,极大推动了优化算法的应用普及。 展望未来,优化器研究的复兴不仅限于算法性能指标的提升,更体现在理论与实践的紧密结合。
实验数据带来的直观和及时反馈,协助理论家精准定位研究盲点,加快理论模型对真实训练行为的建模能力。随着相关工具链的完善,包含Muon及相关继承者在内的一阶优化器生态系统有望逐渐形成,成为深度学习领域不可或缺的技术基石。 对于优化研究者而言,目前正是大力探索经验主义路径的黄金时代。拥抱训练大规模变换器模型的挑战,通过系统的实验设计和数据分析推动优化器持续演进,将有望带来革命性变化。同时,这一过程也鼓励跨学科协作,融合统计学、数值分析和计算机科学的优势,为优化理论注入新的活力和视角。 总之,随着人工智能应用场景的不断扩大和模型规模的迅猛增长,传统优化器面临空前考验。
依托于实践导向的经验研究,首次有算法成功破局AdamW的统治地位,预示着一阶优化器领域正迎来突破性发展。理论的逐步深化与实验的持续推动相辅相成,令优化算法朝向更高效、更稳定、更智能的方向迈进。未来,我们有望见证优化器技术翻开崭新篇章,助力神经网络训练迎来更广阔的可能性和更深远的影响。